随着对 Prometheus, Alertmanager 深入了解,我们配置的告警通知可读性提高了不少。
但是有一个问题不断困扰着我们,现象大致为:
在逻辑上我们认为是同一条的告警内容,在告警通知里面出现多次,而且已经过时告警还在不断发(一直报)。
我们可以将这个问题简单总结为以下几点:
- Prometheus Rule 一条查询结果,在 Alertmanager 却对应了多条警告。
- Alertmanager 里面有警报一直处于未恢复的状态(没有收到 Prometheus 发送的 resolved 请求)
出现问题的原因
一开始我怀疑,是不是 Prometheus 向 Alertmanager 发送的 Resolved 通知有丢失, 导致部分历史警告一直处于未恢复状态。
经排查,发现 Prometheus 和 Alertmanager 都未重启过,所以理论上不存在丢失通知的情况,即使有也是很低频的,无法解释问题 2 的大量情况。
为了彻底搞清楚这个问题,我们有必要先弄清楚 Prometheus 中的 Rule 触发产生的告警在 Alertmanager 中是怎么对应的。
1. 如何区分两条告警
根据 Prometheus common/alert 中的代码可知,所有具有相同 Labels 的告警为同一告警。
那如何才算具有相同 Labels 呢,它的计算逻辑为对一个 map 按照 key 排序,然后依次对 key, value 取值,做 hash 计算,代码逻辑大致为:
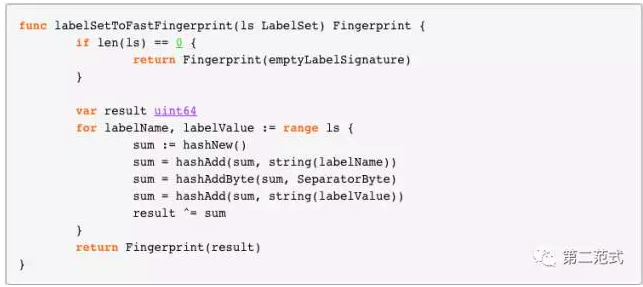
2. Prometheus 产生一条 Alert 的逻辑
Prometheus 执行配置中的 Rule 查询的时候,如果有满足条件的结果,就会产生对应告警,而告警条目数与查询出的纪录条数一致。
当产生告警的时候,一条告警的 Labels 中除了 Prometheus 自动加入的 alertname,还有对应 Rule 定义的 Labels。
3. Alertmanager 是如何分辨告警
首先,对于 Alertmanager ,它收到的告警是一个打平的数组。
因为每个告警的 Labels 里面包含了 Rule 的 alertname,区别是否是相同的告警,对 Alertmanager 而言,只需查看是否具有完全相同的 Labels 即可。
Alertmanager 中的代码大致为:
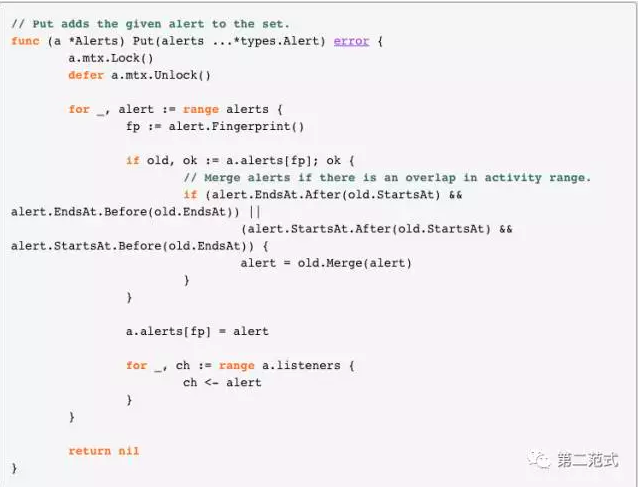
现在,我们已搞清楚了 Prometheus 产生告警和 Alertmanager 中判断是否为相同告警的逻辑,是时候 review 一下我们的配置了。
我们很多业务类监控规则的写法类似这样:

可以看到,这条规则中自定义了一个 value 属性,它的值是创建告警的时候的查询结果(一个变量),当这条规则触发后,Alertmanager 接收到的告警 大致是这样:
{alertname: "xxxx", value: , xxx}
因为告警的 value 是一个动态变化值,所以当 Prometheus 触发恢复告警的时候,实际上会产生了一条全新的告警恢复,因为它和以前触发的告警的 value 不同了,所以实际上 Alertmanger 正在告警的通知并没有收到对应的恢复通知。
故老得告警无法收到恢复通知,新的告警(value不同)又不断产生,最终就会导致以上两个问题。
在弄清楚问题来龙去脉以后,解决起来自然简单:
- 检查 Rule 配置文件,将 value 参数 放到 ANNOTATIONS,重新加载配置。
- 删除 Alertmanager 的历史数据,重启。
总结
配置 Prometheus Rule 时候,自定义的 Lables 不能存在变量,不然会产生多条告警。