我们都知道 Prometheus counter 类型的值是不断累加的,意味着“理论”它是单调递增。
为什么是理论呢,这是因为指标的数据都是由客户端上报的,当客户端进程重启或显式调用reset函数,对应实例上报的指标就会重置为 0,从而导致上报结果出现递减的情况。
查看 counter 某个时刻的采样值一般没有太大意义,通常我们会使用一个区间的差值或者速率来反应这段时间的变化情况。比如我们会用它来计算最近1分钟的磁盘 IO、最近5分钟状态码为 500 的请求数。
针对 counter 类型的指标,Prometheus 提供了 rate、irate、increase、resets 四个专有函数来处理。
一旦使用这四个函数,该指标就被视为 conter 类型,对采样点下降的情况会做特殊处理。
各查询函数详解
假设我们有一个 http_requests_total{code="200"} 的 counter 类型指标,它最近1分钟的采样数据如下:
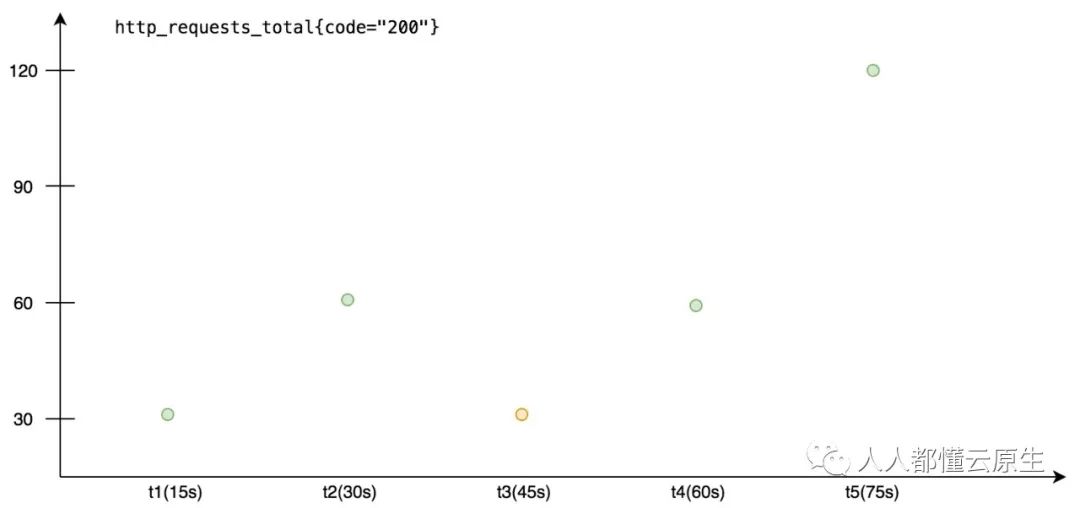
- 数据上报周期为 15s。
- 指标在 30s~45s 之间出现了重置, 黄色点表示重置后新上报的结果。
下面我们就根据上图的数据来详细讲解 counter 相关函数的实现原理。
rate
首先必须讲解的就是 rate ,因为它是 counter 类型使用最多的函数。
它主要用于计算时间范围内某指标的速率,简单计算方法就是△v/△t。但如我们一开始提到,counter 类型的指标存在值重置的情况,如果只是简单使用时间窗口两端的值相减,显然不够合理,那 Prometheus 是如何解决这个问题的呢?
这里主要有两个思路。
方法一:将时间窗口内的所有采样点依次进行差值计算,如果发现后一个点比前一个点的值小,那么直接使用该点的值做为对应差值。
方法二:将时间窗口的最后一个点的值减去第一个点的值得到一个 △v,然后再遍历窗口内所有点,如果发现有重置的情况,就将 △v 加上重置点的前一点的值。
根据以上两种方法计算 rate(http_requests_total{code="200"}[1m]) 结果如下:
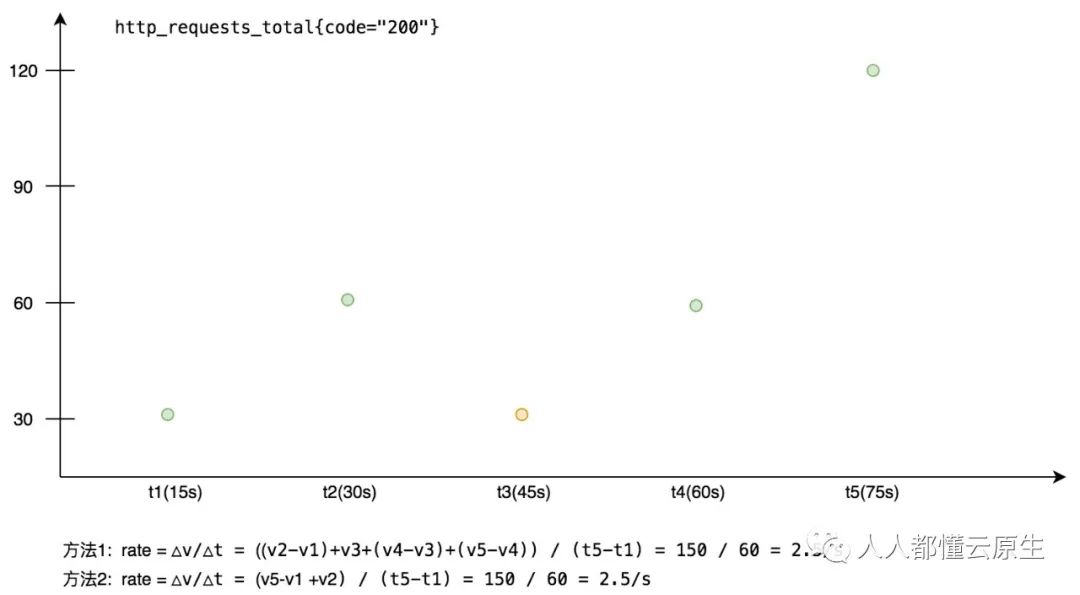
可以看到以上方式计算结果是一样的,目前 Prometheus 使用的是第二种计算方法。
irate
irate 函数的作用与 rate 一致,但它在计算的时候不会使用时间窗口的所有点,而是直接使用最后两个点来计算。
△v 的计算满足如下规则:
- 如果最后一个点的值 >= 倒数第二个的点, 那么 △v = 两点差值。
- 如果最后一个点的值 < 倒数第二个的点, △v = 最后一点的值。
△t 直接取最后两点的时间差值即可。
所以 irate(http_requests_total{code="200"}[1m]) 计算结果如下:
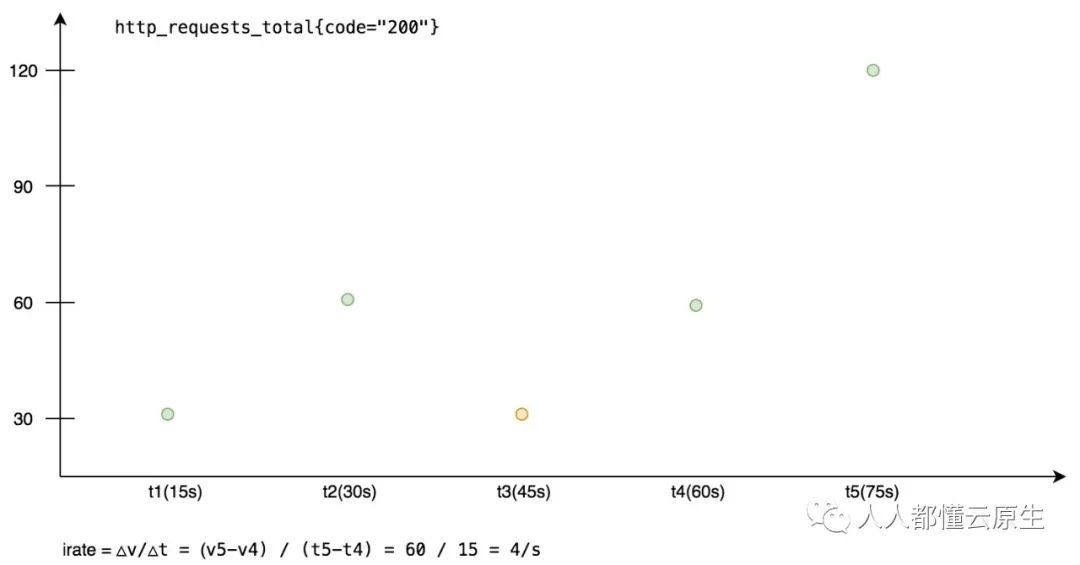
可以看到使用 irate 的计算结果没有 rate 平滑,因为它只使用最后两个点的结果来表示整个区间,但相对而言使用 irate 计算更加高效。
increase
increase 表示一个时间窗口的变化值,它完全等于 rate 函数中的 △v, 即永远存在这样的等式 increase(v) = rate(v) * △t。
就本例而言,increase(http_requests_total{code="200"}[1m]) 为 150。
resets
resets 用于计算一个时间窗口内指标被重置的次数,只要采样点的值有减小,就对应 +1。
就本例而言,resets(http_requests_total{code="200"}[1m]) 为 1。
总结
Prometheus 的 counter 类型指标主要用到 rate、irate、increase、resets 这四个函数,平时我们用的最多的是 rate 和 irate。
rate 和 irate 在计算 △v 的时候,都会自动处理值重置的情况,使用 rate 计算的结果更加平滑,而 irate 更加高效,大家可以根据自己实际情况来选择对应函数。
至此,本篇关于 Prometheus counter 相关的四大函数的实现原理就介绍完了,希望大家以后在使用 PromQL 的时候,都能选择最合适的函数。