随着云和云原生的普及,软件基础设施由虚拟机、云主机慢慢转变为容器、K8S 以及 Serverless/FaaS,软件架构也从单体过渡到微服务和完全分布式架构。
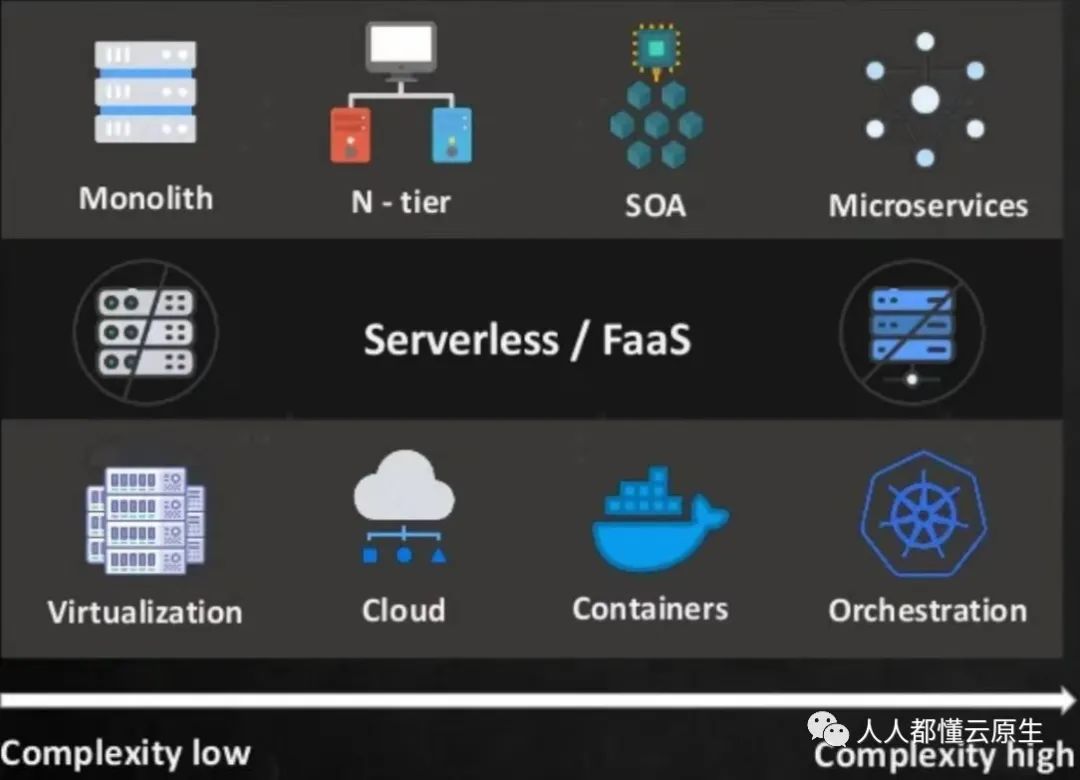
虽这一改变大大提升了系统的稳定性和横向扩缩容能力,但也带来了新的挑战:
- 失去底层硬件设施的控制能力。
- 系统调用链路变多而复杂。
- 临时调度/销毁容器在不断增加。
- 安全攻击面不断增加。 ….

可以看到现在的系统是如此复杂,在这种复杂之下如何快速定位问题、又如何在最短时间恢复,已然变成了一个巨大的挑战,而传统的监控告警显得不堪重负。
所以我们不禁反思,在云原生时代,我们需要怎样的监控,它应该具备哪些特性?
大家最后反思的结果就是可观测性(Observability)。
什么是可观测性
“可观测性”不算一个新词,反而变成了一个 buzzword,你几乎可以听到人人都在谈论它,那到底什么是可观测性呢?
就像一千个人有一千个哈姆雷特一样,不同人对“可观测性” 有不同认识,国外主流博文一般是这样介绍可观测性。
Observability is the ability to measure the internal states of a system by examining its outputs
简而言之,可观测性是通过从系统内部收集各种可观测的数据来了解系统内部正在发生的事情,从而找到根因。
所以本质上它是一门数据收集和分析的科学。
和传统监控区别
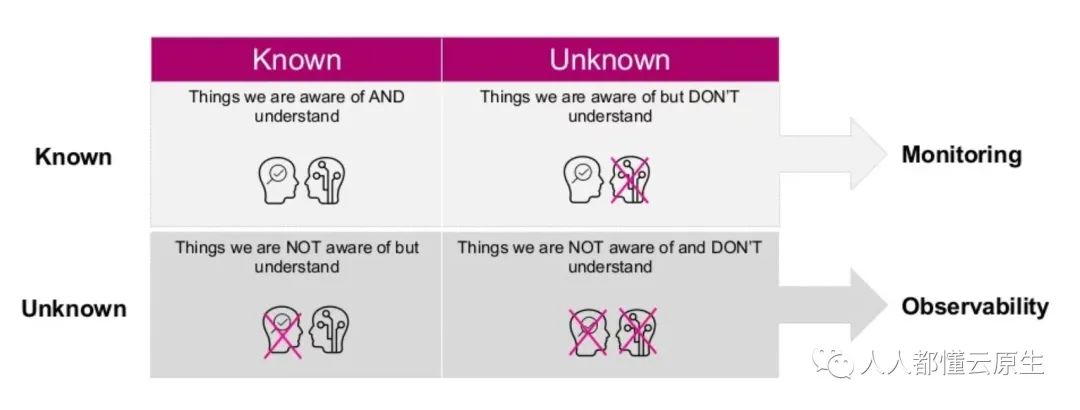
如图,我们可以将系统中的信号数据根据其价值和我们对其认知划分为4个纬度,及 Known Knowns、Unknown Knowns、Known Unknowns、Unknown Unknowns。
传统监控一般是基于系统的事实情况(Knowns),让你有能力感知系统的异常情况,但它对那些未知的情况(Unknowns)就无能为力了。
而可观测性具备这样的能力,能够帮助你了解以前从未了解的情况(Unknowns),知道系统哪里有问题,根因是什么。
今天的 Knowns 对于昨天而言还是 Unknowns,可观测性能够不断帮助我们了解冰山下(复杂系统)的未知世界。
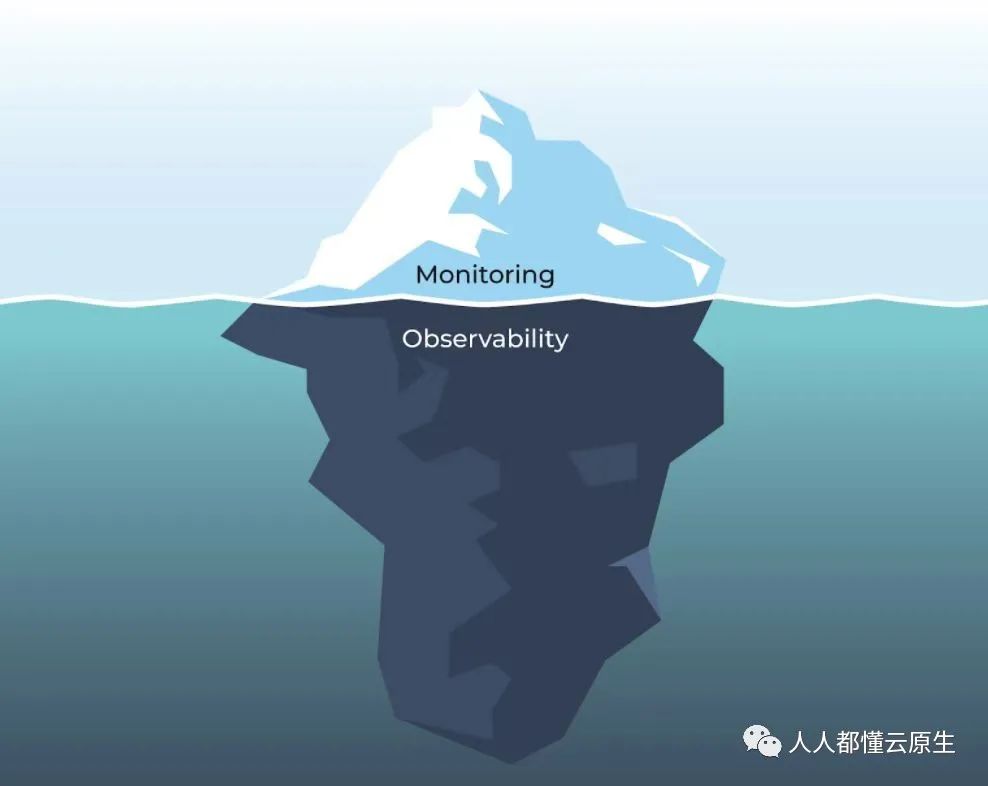
可观测性数据分类
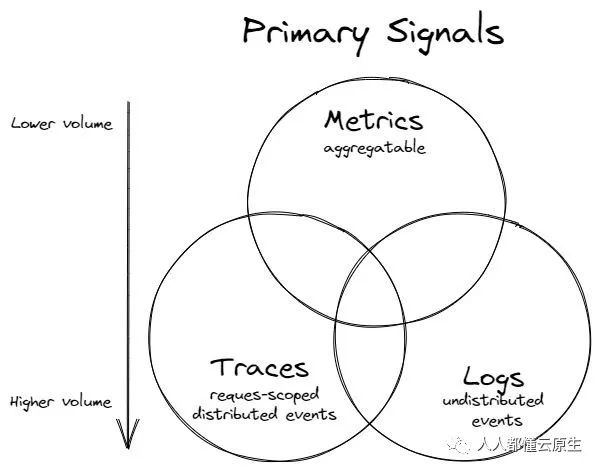
大家可能很早就听说过可观测性的三支柱(three pillars),及 metrics、logs、traces,将它们称为支柱(pillar)容易让人产生歧义。
支柱就像一个房子的均匀受力支撑点,好像它们缺一不可,而事实上,metrics、logs、traces 它们都可以单独存在,目前大家的系统往往只存在 logs 和 traces。
所以在可观测白皮书中,将这些可观测性的数据统一称为信号(Signals),而主要的信号除了 metrics、logs、traces 之外,还增加例如 profiles、dumps 等。
不同纬度的数据(信号)在时间和空间(进程)上具有一定相关性,它们通过类似 Exemplar / 资源标签进行相关联,你可以根据这些相关性进行快速定位。
总结
本篇作为可观测性系列文章第一篇,主要讲解了可观性产生的背景、它与传统监控的区别以及其数据分类等内容。
目前云原生可观测性版块非常火热,很多开源项目都在不同信号数据的采集、存储、分析上发力,其中最典型的项目包括 Promtheus、Loki、Tempo、OpenTelemetry 等,在后面的文章中我们将重点介绍下它们。
可观性文章系列:
- 简介
- 信号和后端技术
- 可观测性 2.0 之 OpenTelemetry