熟悉 Prometheus TSDB 的朋友应该都知道,Prometheus 是不支持乱序数据写入的,因为它对乱序数据写入有两个限制:
- 同一 series 要求数据写入不可以乱序(即: 时间相对靠前的数据需要先写入,时间靠后的数据后写入),若乱序到达的数据则会拒绝写入,这种错误称为out of order。
- Head 中的不同 series 写入要求必须在同一个时间窗口(block range)内,否则会拒绝写入。假设一个 TSDB 的 block range 为 2h,其中最新的 sample a写入数据的时间戳为 7:03,这时在内存中的 block 存储的时间范围 6:00-7:03 (block会进行时间对齐),但是如果此时写入一个 5:50 的 series b 数据则会被拒绝写入,这种错误称为 out of bound。
本文为了方便讨论,暂时将以上两种情况统称为 OOO 问题,由于它的存在,极大限制了以 Prometheus TSDB 作为底层存储的开源项目的使用场景。
什么情况会出现 OOO
如果只有一个 scraper,其抓取间隔配置适当,理论在同一个 IDC 中理论不会出现 OOO,但在实际使用场景中,有以下情况会遇到 OOO 问题。
- 由于一些用户行为,例如要对数据进行数据聚合,或者 IoT 设备会上传离线数据等场景,使得产生的数据源本身就是 out-of-bound 和 out-of-order。
- 当从多个 targets 采集数据时,其中一些 target 节点由于网络或者其他原因导致写入 Prometheus 的时延在 1个小时以上时则会造成 out-of-bound。
- 当采集的数据通过 Kafka 等消息队列中间件转发时,由于不同消费者的消费速度不一致则会造成 out-of-bound 和 out-of-order。
这个问题的解决确实比较棘手,笔者曾经为了支持 IoT 穿戴场景,试图在 Prometheus 的 backfilling 功能上添加任意时间返回的乱序数据写入的支持,最终失败告终,最近恰好看到 Mimir v2.2.0 版本发布,提到对该功能的支持,所以想看看它的具体实现逻辑。
Mimir 实现原理
下面我们来看看 Mimir 的实现原理,其相关代码已合并到 mimir_prometheus 中,相信不久将来会合并到 Prometheus 仓库。
这个代码修改大大利用了已有的代码结构,从而以较小代价实现此功能,其核心修改包括乱序数据写入、统一查询、乱序数据压缩三大块,下面我们就一起来看下具体实现。
乱序数据写入
乱序数据的写入流程大致如下:

1、扩展 memSeries(从属于单个series),用于存储头块中写入的乱序数据。
# grafana/mimir-prometheus/tsdb/head.go#L1822
type memSeries struct {
...
oooMmappedChunks []*mmappedChunk // Immutable chunks on disk containing OOO samples.
oooHeadChunk *oooHeadChunk // Most recent chunk for ooo samples in memory that's still being built.
firstOOOChunkID chunks.HeadChunkID // HeadOOOChunkID for oooMmappedChunks[0]
...
}
# oooHeadChunk 定义
type oooHeadChunk struct {
chunk *chunkenc.OOOChunk
minTime, maxTime int64
}
type sample struct {
t int64
v float64
}
type OOOChunk struct {
samples []sample
}
其中:
oooHeadChunk用于乱序数据内存写入。oooMmappedChunks用于存储写满 chunk 做的 M-Map 磁盘映射。
2、新增 insert 方法,实现乱序数据插入,每次只插入到 oooHeadChunk 中,在插入的时候,会按照 sample 的时间(t) 进行排序,如果插满(默认 30个,可以通过 oooCapMax 配置),将触发 oomHeadChunk 落盘和 M-Map 映射。
# grafana/mimir-prometheus/tsdb/head_append.go#L669
func (s *memSeries) insert(t int64, v float64, chunkDiskMapper chunkDiskMapper) (inserted, chunkCreated bool, mmapRef chunks.ChunkDiskMapperRef) {
c := s.oooHeadChunk
if c == nil || c.chunk.NumSamples() == int(s.oooCapMax) {
// Note: If no new samples come in then we rely on compaction to clean up stale in-memory OOO chunks.
c, mmapRef = s.cutNewOOOHeadChunk(t, chunkDiskMapper)
chunkCreated = true
}
ok := c.chunk.Insert(t, v)
....
return ok, chunkCreated, mmapRef
}
# grafana/mimir-prometheus/tsdb/chunkenc/ooo.go#L26
func (o *OOOChunk) Insert(t int64, v float64) bool {
// find index of sample we should replace
i := sort.Search(len(o.samples), func(i int) bool { return o.samples[i].t >= t })
if i >= len(o.samples) {
// none found. append it at the end
o.samples = append(o.samples, sample{t, v})
return true
}
if o.samples[i].t == t {
return false
}
// expand length by 1 to make room. use a zero sample, we will overwrite it anyway
o.samples = append(o.samples, sample{})
copy(o.samples[i+1:], o.samples[i:])
o.samples[i] = sample{t, v}
return true
}
3、新增 wbl 文件,用于 OOO 数据写入 Log 记录 。
# grafana/mimir-prometheus/tsdb/head_append.go#L661
func (a *headAppender) Commit() (err error) {
...
collectOOORecords()
if a.head.wbl != nil {
if err := a.head.wbl.Log(oooRecords...); err != nil {
level.Error(a.head.logger).Log("msg", "Failed to log out of order samples into the WAL", "err", err)
}
}
...
}
wbl 中的 Log 信息主要包括两种,分别为 record.RefMmapMarker 和 samples , 这里新增 wbl 文件,而不直接复用 wal,主要出于以下考虑:
- 解耦,对历史代码做到尽量小修改。
- OOO 数据,在压缩时可以直接将内存的
oooHeadChunk全部刷到磁盘,不需要做 Checkpoint,从而简化了逻辑。
好了,到目前为止,我们基本完成了乱序数据的写入,下面我们来看看乱序数据的查询。
统一查询
统一查询主要指除了持久块(blocks)的数据和 Head 中顺序写入的数据外,还要包括 Head 中的乱序写入的数据,整体流程如下图:
1、从图中我们可以看到,每次查询进入时,Mimir 会根据查询时间范围从持久块、Head 顺序 chunks 以及 乱序 chunks 中找到合适的 series chunks,以此构建对应的 Querier,具体代码如下:
// grafana/mimir-prometheus/tsdb/db.go#L1751
func (db *DB) Querier(_ context.Context, mint, maxt int64) (storage.Querier, error) {
...
if inOrderHeadQuerier != nil {
blockQueriers = append(blockQueriers, inOrderHeadQuerier)
}
if outOfOrderHeadQuerier != nil {
blockQueriers = append(blockQueriers, outOfOrderHeadQuerier)
}
return storage.NewMergeQuerier(blockQueriers, nil, storage.ChainedSeriesMerge), nil
}
2、memSeries 中新增 oooMergedChunk 方法,用来处理 OOO 的数据查询,实现代码如下:
// grafana/mimir-prometheus/tsdb/head_read.go#L375
func (s *memSeries) oooMergedChunk(meta chunks.Meta, cdm chunkDiskMapper, mint, maxt int64) (chunk *mergedOOOChunks, err error) {
...
// We create a temporary slice of chunk metas to hold the information of all
// possible chunks that may overlap with the requested chunk.
tmpChks := make([]chunkMetaAndChunkDiskMapperRef, 0, len(s.oooMmappedChunks))
oooHeadRef := chunks.ChunkRef(chunks.NewHeadChunkRef(s.ref, s.oooHeadChunkID(len(s.oooMmappedChunks))))
if s.oooHeadChunk != nil && s.oooHeadChunk.OverlapsClosedInterval(mint, maxt) {
// We only want to append the head chunk if this chunk existed when
// Series() was called. This brings consistency in case new data
// is added in between Series() and Chunk() calls
if oooHeadRef == meta.OOOLastRef {
tmpChks = append(tmpChks, chunkMetaAndChunkDiskMapperRef{
meta: chunks.Meta{
MinTime: meta.OOOLastMinTime, // we want to ignore samples that were added before last known min time
MaxTime: meta.OOOLastMaxTime, // we want to ignore samples that were added after last known max time
Ref: oooHeadRef,
},
})
}
}
for i, c := range s.oooMmappedChunks {
chunkRef := chunks.ChunkRef(chunks.NewHeadChunkRef(s.ref, s.oooHeadChunkID(i)))
// We can skip chunks that came in later than the last known OOOLastRef
if chunkRef > meta.OOOLastRef {
break
}
if chunkRef == meta.OOOLastRef {
tmpChks = append(tmpChks, chunkMetaAndChunkDiskMapperRef{
meta: chunks.Meta{
MinTime: meta.OOOLastMinTime,
MaxTime: meta.OOOLastMaxTime,
Ref: chunkRef,
},
ref: c.ref,
origMinT: c.minTime,
origMaxT: c.maxTime,
})
} else if c.OverlapsClosedInterval(mint, maxt) {
tmpChks = append(tmpChks, chunkMetaAndChunkDiskMapperRef{
meta: chunks.Meta{
MinTime: c.minTime,
MaxTime: c.maxTime,
Ref: chunkRef,
},
ref: c.ref,
})
}
}
...
}
乱序数据压缩
由于在 Head 中的 OOO 数据可能存在跨越多个 Block range 的情况,为了重用 Prometheus 的 compact 功能,Mimir 会将 OOO chunks 拆分成若干个 Block,这些 Blocks 按照 Head Block range 对齐,然后再针对对应的 Block 范围从 Block head 中的 OOO Chunks 中去查询对应范围的数据即可,主要流程如下图:
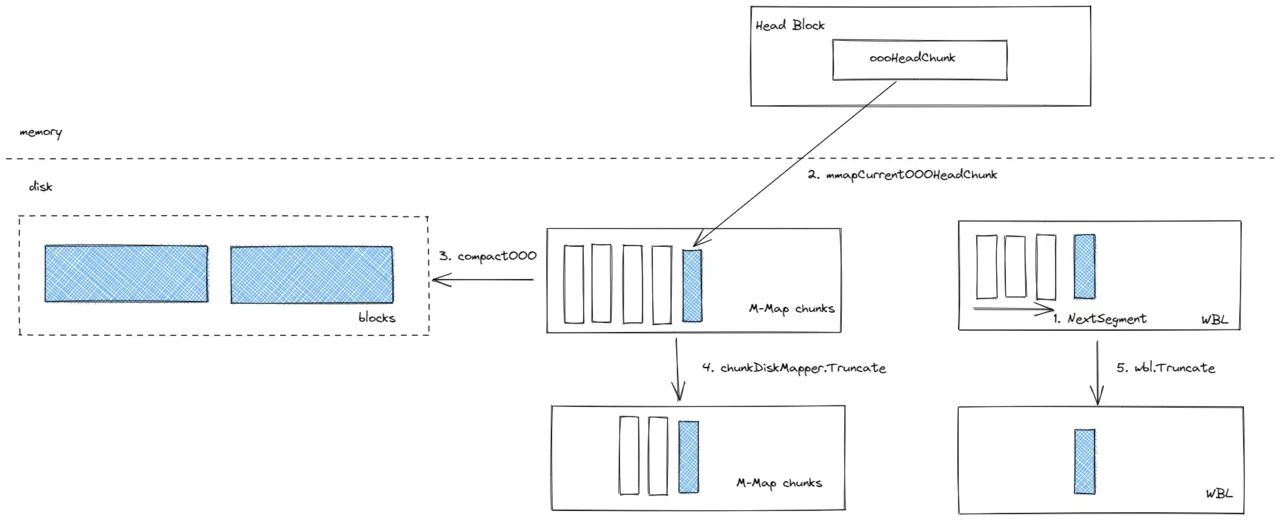
1、压缩开始,WBL 新建一个 Segment,用于新的 OOO 数据写入。 2、将内存中的 OOO数据刷到磁盘,变为 oooMmapedChunks。 3、按照 Head 中的 OOO 数据的时间范围,生产对应 Block,并依次按照 Block 的时间范围从 Head 中的 oooMmapedChunks 中筛选对应数据,进行压缩。 4、存储 MmapedChunks 的 segment 回收。 5、WBL 目录下的 segment 回收。
压缩核心代码如下:
// grafana/mimir-prometheus/tsdb/compact.go#L577
func (c *LeveledCompactor) compactOOO(dest string, oooHead *OOOCompactionHead, shardCount uint64) (_ [][]ulid.ULID, err error) {
...
outBlocks := make([][]shardedBlock, 0)
outBlocksTime := ulid.Now() // Make all out blocks share the same timestamp in the ULID.
blockSize := oooHead.ChunkRange()
oooHeadMint, oooHeadMaxt := oooHead.MinTime(), oooHead.MaxTime()
ulids := make([][]ulid.ULID, 0)
for t := blockSize * (oooHeadMint / blockSize); t <= oooHeadMaxt; t = t + blockSize {
mint, maxt := t, t+blockSize
outBlocks = append(outBlocks, make([]shardedBlock, shardCount))
ulids = append(ulids, make([]ulid.ULID, shardCount))
ix := len(outBlocks) - 1
for jx := range outBlocks[ix] {
uid := ulid.MustNew(outBlocksTime, rand.Reader)
meta := &BlockMeta{
ULID: uid,
MinTime: mint,
MaxTime: maxt,
OutOfOrder: true,
}
meta.Compaction.Level = 1
meta.Compaction.Sources = []ulid.ULID{uid}
outBlocks[ix][jx] = shardedBlock{
meta: meta,
}
ulids[ix][jx] = meta.ULID
}
err := c.write(dest, outBlocks[ix], oooHead.CloneForTimeRange(mint, maxt-1))
...
}
最终生成的 Block 的 meta.json 会新增一个 out_of_order 字段,用于标注 Block 的类型。
{
"ulid": "01G8TQ2WQ72C79WTHPWRESZN7V",
"minTime": 1658714400000,
"maxTime": 1658721600000,
"stats": {
"numSamples": 300,
"numSeries": 1,
"numChunks": 5
},
"compaction": {
"level": 1,
"sources": [
"01G8TQ2WQ72C79WTHPWRESZN7V"
]
},
"version": 1,
"out_of_order": true
}
这些批量生成的 OOO Blocks 会经过纵向压缩合并回已经压缩过的循序 Block 中。
总结
本文我们通过源码了解 Mimir 乱序数据写入的逻辑,它主要包括三个部分:
- 新增
insert方法用于 Head 中乱序数据插入。 - 新增
oooMergedChunk方法用于查询 Head 中的 OOO chunks 数据。 - 新增
compactOOO方法用于 OOO 数据的压缩,它一次可以压缩多个 Blocks,这些 Block 按照时间范围对齐,它们最终会合并回顺序的 Blocks。
如果你正在使用 Prometheus 而恰好遇到乱序数据写入的问题,不妨尝试使用 mimir 或者 mimir-promethes ,你只需简单配置 storage.tsdb.out_of_order_time_window 参数即可写入任意时间范围的乱序数据。
参考文章