title: “Mimir 源码分析 (四):算子下推之高基数分片查询” subtitle: date: 2022-08-22 20:40:15+0800 thumbnail-img: /images/mimir/source/04/01.jpg
cover-img:
share-img:
tags: [grafana, mimir]
在 Mimir 集群中运行10亿活跃指标,不只要求抓取保存这么多 metrics 数据,同时也要能够高效的查询这些数据。
如果使用 PromQL 的单线程引擎,这种查询就会受到单核 CPU 的能力影响。当处理高基数查询时,查询性能会比较差。Mimir 带来了一种边缘计算或者叫做算子下推的方式,对高基数查询进行优化。
查询拆分
Mimir 采用两种策略将单个查询拆分成多个 CPU/机器可以并发执行的子查询。
- 根据时间进行拆分(时间拆分)
- 根据 series 的分片进行拆分(查询分片)
时间拆分,是将1个长区间查询,切分成多个子查询。如果一个查询的时间范围跨越多天,该查询会被拆分成多个1天的查询,每个查询并发运行。
查询分片,将 series 数据切成多个分片。每一个分片承载了一次查询中的部分数据,所以一次完整查询,分解成多个子查询,被分散在多个机器中执行。随后这些子查询再进行汇聚,将最终结果返回给客户端。
经过官方严格测试,对 CPU 密集型的高基数查询,进行查询分片,可以将大部分的查询耗时降低10倍。
比如有1个可以拆分成两个分支的查询语句,时间跨度为7day,
sum(rate(failed[1m])) / sum(rate(total[1m]))
假设查询分片为3,
最终拆分成的查询语句如下:
sum(
concat(
sum (rate(failed{__query_shard__="1_of_3"}[1m]))
sum (rate(failed{__query_shard__="2_of_3"}[1m]))
sum (rate(failed{__query_shard__="3_of_3"}[1m]))
)
)
/
sum(
concat(
sum (rate(total{__query_shard__="1_of_3"}[1m]))
sum (rate(total{__query_shard__="2_of_3"}[1m]))
sum (rate(total{__query_shard__="3_of_3"}[1m]))
)
)
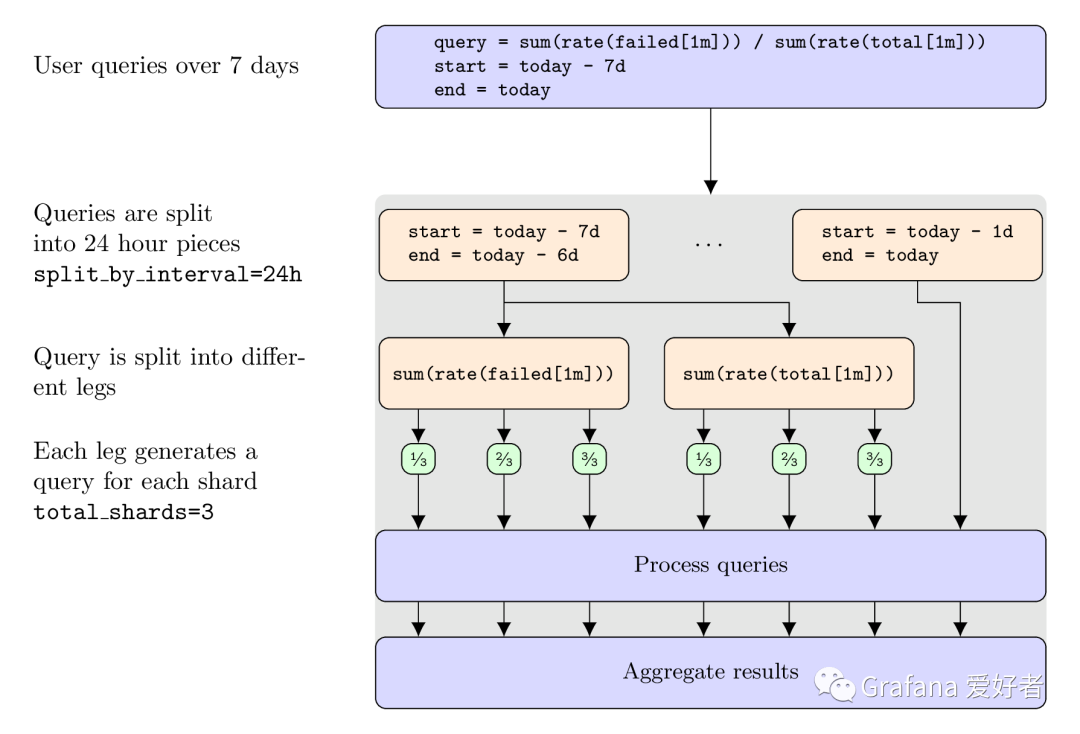
拆分流程如下:
- 首先根据配置,整个查询会根据24h进行拆分。
- 然后每一天的查询,分为两大分支,这里叫做 legs,即原 promql 可以被拆成几部分,被称为 legs。
- 最后,每一个 leg 内部,由 concat 再次根据查询分片,进行子查询拆分。
最终我们看到,这个查询被拆分成 723=42个子查询。
如何开启分片查询
我们根据前面介绍的单体部署模式,将 mimir.yaml 的配置最后,增加如下配置:
frontend:
parallelize_shardable_queries:true
该配置表示打开分片查询功能。
同时保持 compactor 的 split&merge 的配置:
overrides:
demo:
compactor_split_and_merge_shards: 2
compactor_split_groups: 2
重新部署即可,检查一下,查询分片默认配置为:
query_sharding_total_shards: 16
query_sharding_max_sharded_queries: 128
其中 query_sharding_total_shards 表示每个 leg 可以拆分的分片数,即__query_shard__=”1_of_3”中的3;
query_sharding_max_sharded_queries 表示本次原始查询可以分解的最多分片数。这个在leg较多时,比较实用,防止leg 过多导致的分片风暴。
一个长长的例子
现在官方的单体 metrics 中有1个查询指标 activity_tracker_failed_total,进行时间跨度为24h的如下查询:
sum(rate(activity_tracker_failed_total{pod="mimir-3"}[5m])) + sum(rate(activity_tracker_failed_total{pod="mimir-2"}[5m]))
总体查询流程如下:
query_front 模块
根据默认分片配置 query_sharding_total_shards:16,把上述查询语句,拆分成如下查询:
sum(__embedded_queries__{__queries__=
"{
"Concat":["sum(rate(activity_tracker_failed_total{__query_shard__="1_of_16",pod="mimir-3"}[5m]))",
"sum(rate(activity_tracker_failed_total{__query_shard__="2_of_16",pod="mimir-3"}[5m]))",
...
"sum(rate(activity_tracker_failed_total{__query_shard__="16_of_16",pod="mimir-3"}[5m]))"]}})
+
sum(__embedded_queries__{__queries__=
"{
"Concat":["sum(rate(activity_tracker_failed_total{__query_shard__="1_of_16",pod="mimir-2"}[5m]))",
"sum(rate(activity_tracker_failed_total{__query_shard__="2_of_16",pod="mimir-2"}[5m]))",
...
"sum(rate(activity_tracker_failed_total{__query_shard__="16_of_16",pod="mimir-2"}[5m]))"]}})
querier收到32个子查询
上面产生了32个查询请求,随后 query_front 将这32个查询,推送给querier 进行查询,querier 收到32个子查询,在grafana控制台也验证了本次拆分的查询统计数为32,
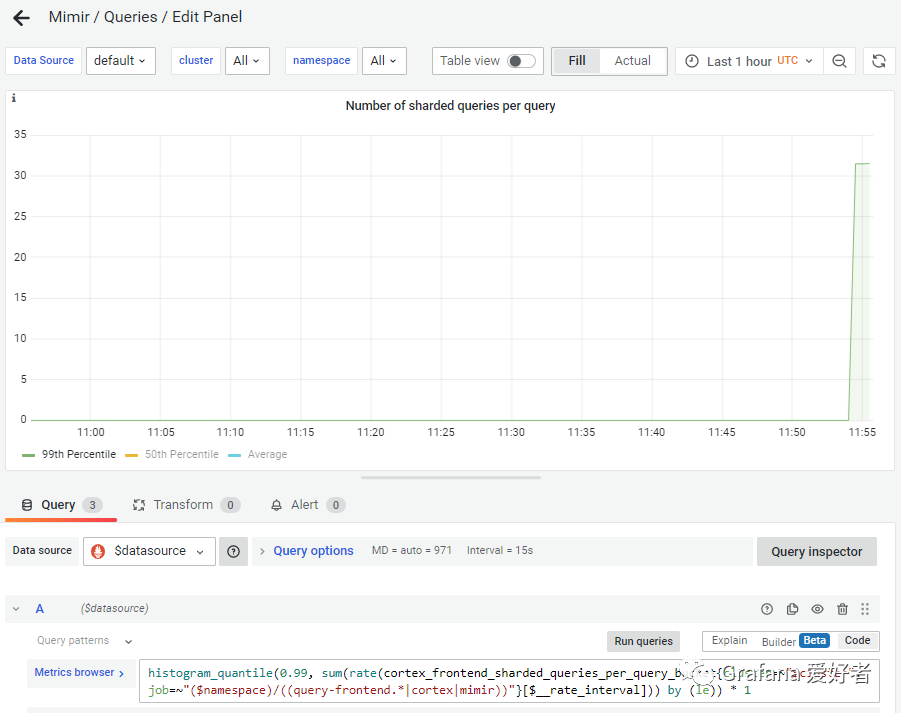
querier 发出的其中一个查询请求如下:
user=demo method=querier.Select level=debug hint.func=rate start="2022-07-15 08:03:15 +0000 UTC" end="2022-07-15 08:38:15 +0000 UTC" step=15000 matchers="__query_shard__=\"13_of_16\",pod=\"mimir-2\",__name__=\"activity_tracker_failed_total\""
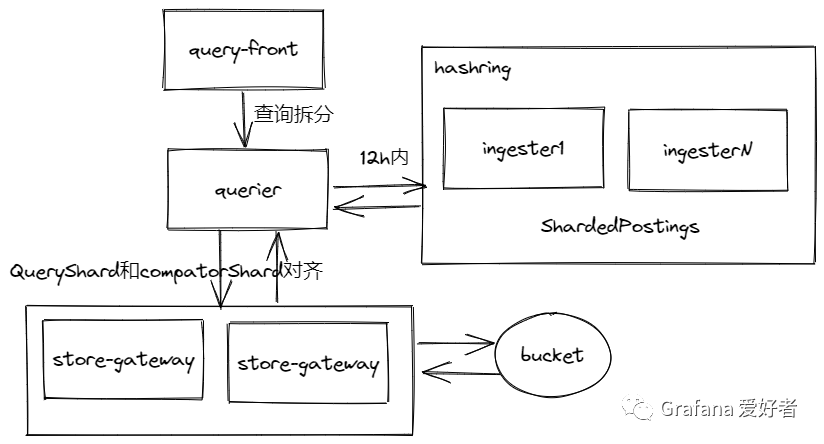
因为时间跨度为12h,querier会同时去 ingester(12h内) 和 store-gateway(12h外) 读取数据。
当去ingester查找数据时
querier 根据 hashring 找到需要通知的ingester节点:
//mimir/pkg/distributor/query.go
func (d *Distributor) QueryStream(ctx context.Context, from, to model.Time, matchers ...*labels.Matcher) (*ingester_client.QueryStreamResponse, error) {
replicationSet, err := d.GetIngesters(ctx)
result, err = d.queryIngesterStream(ctx, replicationSet, req)
ingester无差别收到所有请求消息,并且根据 series 的 label hash 值进行判断。因为 ingester上未压缩的 level- 的 series 存在多副本,且数据之间不存在交集,所有的 ingester 都需要无差别的处理查询请求,才能保证最后数据汇聚的完整性。具体到某一个 ingester,他内部的shardCount是上述例子中的16,shardIndex 为13。
func (i *Ingester) QueryStream(req *client.QueryRequest, stream client.Ingester_QueryStreamServer) error {
numSeries, numSamples, err = i.queryStreamChunks(ctx, db, int64(from), int64(through), matchers, shard, stream)
ss := q.Select(false, hints, matchers...)
//D:\opensource\mimir\vendor\github.com\prometheus\prometheus\tsdb\querier.go
func (q *blockQuerier) Select(sortSeries bool, hints *storage.SelectHints, ms ...*labels.Matcher) storage.SeriesSet {
p = q.index.ShardedPostings(p, hints.ShardIndex, hints.ShardCount)
// 修改了prometheus的tsdb查询逻辑,增加了查询分片和series对齐校验
//mimir\vendor\github.com\prometheus\prometheus\tsdb\index\index.go
// Check if the series belong to the shard.
if hash%shardCount != shardIndex {
continue
}
当去store-gateway查找数据时
每一个子查询,都会组装[store-gateway]-[blockIDs] 的映射关系,去不同的store-gateway查找不同的blockID。注意这一点和ingester不同,因为store-gateway处理的持久化数据,已经被多副本去重、垂直水平压缩合并,每一个store-gareway看到的数据完全一致。这时候只需要给他们分配不同的任务,获取不同的blockID数据即可。
//mimir/pkg/querier/blocks_store_queryable.go
func (q *blocksStoreQuerier) Select(_ bool, sp *storage.SelectHints, matchers ...*labels.Matcher) storage.SeriesSet {
return q.selectSorted(sp, matchers...)
}
func (q *blocksStoreQuerier) selectSorted(sp *storage.SelectHints, matchers ...*labels.Matcher) storage.SeriesSet {
err = q.queryWithConsistencyCheck(spanCtx, spanLog, minT, maxT, shard, queryFunc)
result, incompatibleBlocks := filterBlocksByShard(knownBlocks, shard.ShardIndex, shard.ShardCount)
canBlockWithCompactorShardIndexContainQueryShard
shards[addr] = append(shards[addr], blockID)//此处获取store-gateway和blockID映射关系
如querier的13_of_16请求,会将请求的index和compactor的shard index进行对齐。上一篇文章我们了解到,当compactor开启分片压缩后,会进行split&merge压缩规则,本例中的compactor的shard 有2个分片为:
- 1_of_2
- 2_of_2
进行查询分片和压缩分片对齐的逻辑如下:
func canBlockWithCompactorShardIndexContainQueryShard(queryShardIndex, queryShardCount, compactorShardIndex, compactorShardCount uint64) (result bool, divisibleShardCounts bool) {
// If queryShardCount = compactorShardCount * K for integer K, then we know that series in queryShardIndex
// can only be in the block for which (queryShardIndex % compactorShardCount == compactorShardIndex).
//
// For example if queryShardCount = 8 and compactorShardCount = 4, then series that should be returned
// for queryShardIndex 5 can only be in block with compactorShardIndex = 1.
if queryShardCount >= compactorShardCount && queryShardCount%compactorShardCount == 0 {
wantedCompactorShardIndex := queryShardIndex % compactorShardCount
return compactorShardIndex == wantedCompactorShardIndex, true
}
对所有 knownBlocks 进行考察,当处理 compactorShardIndex=1 的 block 时,当前 queryShardCount=16,queryShardIndex =13,compactorShardCount =2,根据上述程序计算,满足 16>=2 && 16%2==0,那么 wantedCompactorShardIndex = 13%2 =1,所以当前的查询分片索引13,可以去压缩分片索引1上,拿数据。类似的逻辑,查询分片索引15,也需要去压缩分片索引1上取数据。
如此组装的 shards 映射关系信息,去 store-gateway 读历史数据。
query_front汇聚
最终 ingester 和 store-gateway 将数据返回给 query_front 进行汇聚。
查询分片和压缩分片的组合场景
由上述查询分片的处理流程可看到有如下几种组合,我们在下一篇文章分享,在不同组合场景下,查询分片带来的不同效果。
- 查询分片未开启,压缩分片未开启
- 查询分片未开启,压缩分片开启
- 查询分片开启,压缩分片未开启
- 查询分片开启,压缩分片开启
- 查询分片是压缩分片的倍数
- 压缩分片是查询分片的倍数