2022/11/02 这天 Grafana 对外宣称开源其持续性能分析(continuous profiling) 解决方案 Phlare, 在正式认识它之前,我们先来聊聊什么是持续性能分析以及当前开源方案。 首先什么是持续性能分析呢?
“Profiling” 是一种分析程序复杂性的动态方法,例如 CPU 利用率或函数调用的频率和持续时间。 通过 Profiling ,我们可以准确定位应用程序在哪些部分消耗的资源最多。 而 “Continuous profiling” 则更加强大,它增加了时间维度, 可以通过随着时间的推移了解系统资源情况,您可以定位、调试和修复与性能相关的问题(参考文章 https://www.cncf.io/blog/2022/05/31/what-is-continuous-profiling/)。
伴随着云原生可观测性和 FinOps 理念的普及,持续性能分析这一概念也逐渐火了起来,把它当成除可观测性三支柱(metric、log、trace)之外的第四支柱已然成为一种共识。
早在一年前持续性能分析这个领域就诞生了不少开源项目,其中最为耀眼的包括 pyroscope-io/pyroscope 和 parca-dev/parca,这两个笔者都有尝试使用过,它们都支持多种语言SDK 以及 eBPF,集成体验都还不错,那今天 Grafana 又推出了自己的解决方案 Phlare,算是给火热的 CP 领域再添一把柴。
Grafana 推出 Phlare 的考量?
- Grafana 公司作为可观测性全栈解决方案,对新兴类型的遥测数据天然是要跟进的,推出自己的方案,有助于降低用户集成门槛,加深自身平台护城河。
- Phlare 整体架构与 Grafana 其它开源项目架构非常相似,大家对架构、组件的理解都更快。
- Grafana 看板对 Phlare 的支持天然可以做的更好,毕竟是自家产品,迭代速度以及动力更强,更方便打造 All in one 看板。
说了这么多,多一个开源产品的选择总归是有好处的。
Phlare 架构
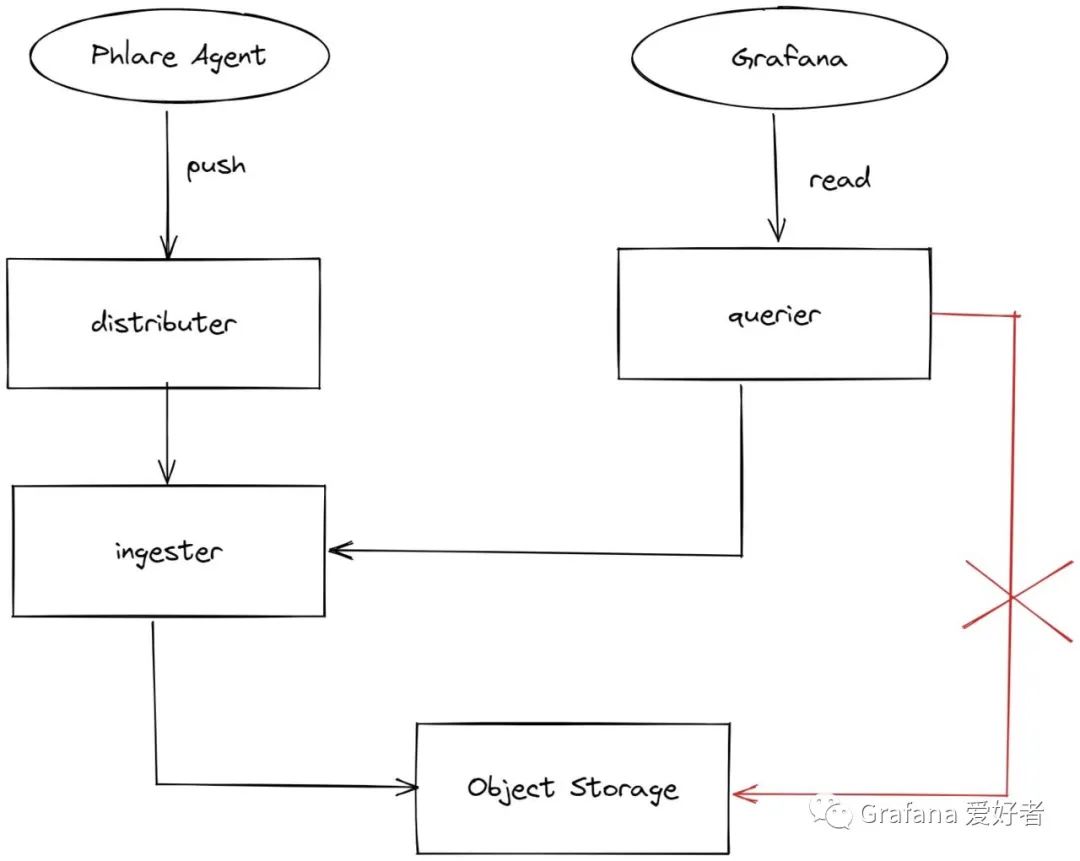
目前 Phlare 的架构如上图,看着是不是很眼熟,没错它和 Mimir 的架构很相似,也包含了 Distributer、Ingester、Querier 等组件。
架构说明:
- Phalre Agent 负责应用分析数据抓取,这个使用了 Parca Agent 的相关代码,很像 Prometheus 的 scraper,支持多种服务发现,APP 需要通过 HTTP 接口导出对应的分析数据。
- Distributer 负责接收分析数据的写入,并进行一些常规的校验,比如 labels 合法性、数据合法性等,然后将合法数据 push 到多个 Ingester 节点(根据配置的副本数),支持根据 labels 进行hash。
- Ingester 主要负责多租户持续性能分析数据的本地存储和查询,每个租户都有单独的 phlaredb 实例,分别存储到不同目录。phlaredb Head 中的数据会定期被截断(内存达到1G或达到配置的最大时间间隔,默认3小时) ,生成一个持久 Block,类似 Prometheus 中的 Head Block 做截断压缩,最后这个持久块会上传到对象存储, 本地 Block 会在磁盘剩余量不足 10GB 或 5%的时候进行清理。
- Querier 负责持续性能分析数据查询,目前只支持从 Ingester 查询数据,暂不支持从对象存储 Block 数据查询。
当前 Phlare 的版本为 v0.1.0, 可以看到它缺少的功能挺多的,比如对象存储存储数据的查询(store-wateway),多副本数据集中去重(类似 Thanos compactor),Grafana Agent 中集成 Phalre Agent。
它大部分功能和 Parca 相似,包括 Agent 抓取,只不过它多了集群管理、多副本存储以及多租户。
Phlare 速体验
虽然 Phlare v0.1.0 缺失的功能还不少,但不影响我们体验它,这里我们模仿 Mimir 也创建了一个 play-with-phlare 的项目,使用 docker-compose 进行快速本地部署。
使用如下命令进行部署:
git clone https://github.com/grafanafans/play-with-phlare.git
cd play-with-phlare
docker-compose up -d
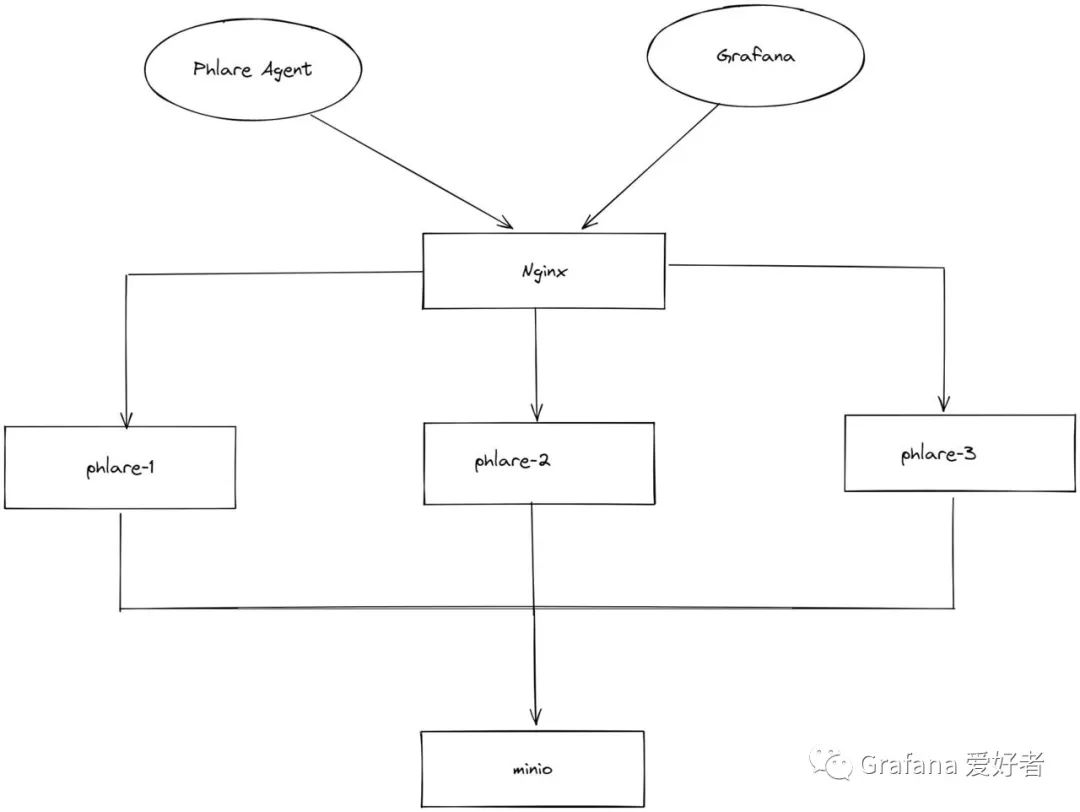
这个命令可以自动完成:
- 启动三个相同的 Phlare 实例,分别为 phlare-1~3,它们都监听 4100 端口。
- 启动一个 Phlare Agent,用于抓取 Phlare 三个实例的分析数据。
- 启动一个 Nginx 作为负载均衡,监听 4100 端口,后端为 Phlare 三个实例。
- 启动一个 Grafana 容器,监听 3000 端口,并通过环境变量 GF_FEATURE_TOGGLES_ENABLE=flameGraph 开启火焰图看板。
- 启动一个 Minio 容器,存储 phlare 的 Block 数据。
部署图如下:
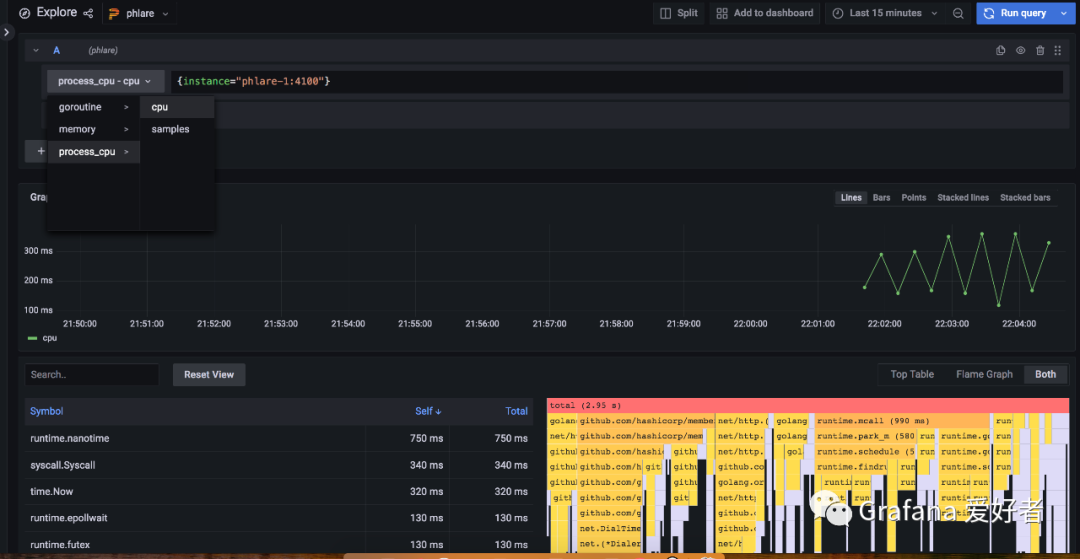
最后通过 http://localhost:3000 页面以及默认的数据源,访问其抓取的分析数据:
配置详情
phlare 实例配置如下:
multitenancy_enabled: true
ingester:
lifecycler:
ring:
kvstore:
store: memberlist
replication_factor: 3
memberlist:
join_members: [phlare-1, phlare-2, phlare-3]
phlaredb:
data_path: /data/ingester
tracing:
enabled: false
storage:
backend: s3
s3:
endpoint: minio:9000
access_key_id: phlare
secret_access_key: supersecret
insecure: true
bucket_name: phlare
配置说明:
- 这里主要使用单实例模式进行部署,它会自动启动所有模块。
- ingester 使用 memberlist 进行集群注册,复制副本数配置为 3。
- 使用 s3 作为 Block 的存储。
- 开启多租户模式。
Agent 配置如下:
target: agent
scrape_configs:
- job_name: 'phlare'
static_configs:
- targets: ["phlare-1:4100", "phlare-2:4100", "phlare-3:4100"]
client:
url: http://load-balancer:4100
tenant_id: demo
配置说明:
- 使用静态配置,分别抓取三个 phlare 实例。
- 通过 lb 地址进行数据的推送,并推送到 demo 这个租户。
总结
我们通过 docker-compose 快速搭建了一个支持多副本、多租户、分级存储的持续性能分析的分布式数据库系统,并通过 Phlare Agent 进行数据抓取,最后再通过 Grafana 看板进行数据查询。 可以看到 Phlare 的部署和配置还是比较简单的,如果您以前熟悉 Parca 之类的开源项目,上手 Phlare 将更快。
目前 Phlare 发布的最新版本为 v0.1.0,虽然它还有不少待开发的功能,但整个框架基本成型,尤其 phlaredb 这套,感兴趣的小伙伴可以尝鲜体验体验。