前面我们已经讲解了 Mimir 数据抓取高可靠方案,今天我们再来讲讲如何使用 Mimir 实现 Prometheus 规则评估和告警管理的高可用,具体包括两部分内容:
Prometheus 规则的高可靠,既要实现规则高可靠存储,又要避免同一时间单个规则组重复评估。 针对触发的告警,既要保障告警消息不丢,又要避免相同告警的重复发送。
Mimir 方案
在 Mimir 中主要使用 ruler 和 alertmanager 两个组件来实现规则评估和告警管理的靠可靠,前提我们使用 s3 集中存储方案,如果使用本地存储,无法实现租户级别的 rules 和 alertmanager 的 sharding。
整体方案如图:
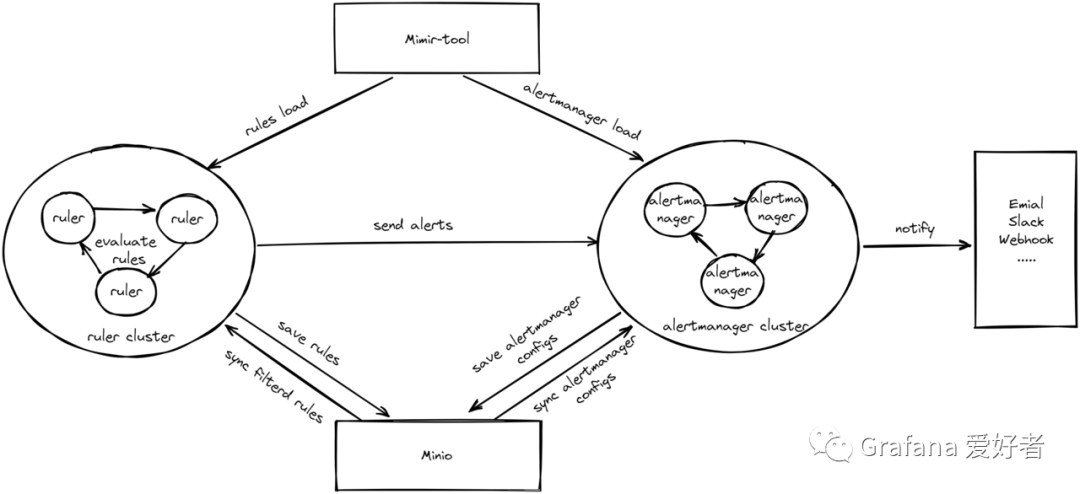
流程说明:
- 多个 ruler 实例组成统一的 ruler 集群,单个 MultitenantAlermanager 维护多个租户级别的 alertmanager,单个租户的多个 alertmanager 组成租户独立的 alertmanager 集群。
- 使用 mimir-tool load rules 命令批量添加租户的 rules 配置,并统一存储到对象存储,兼容 Promtheus rule 文件格式。
- 使用 mimir-tool load alertmanager 添加租户级别的 alertmanager 配置,兼容 Prometheus alertmanager 配置。
- 单个租户的所有规则组会 sharding 分配到不同 ruler 进行评估,如果是 record 规则,产生新的时序数据会写入到 Distributor, 如果是触发的告警,将推送到 MultitenantAlermanager,然后再转发给对应租户的 alertmananger 集群。
- 任意一个 ruler 挂掉,租户的规则组将重新进行 sharding ,所受影响的规则组将重新分配到集群其它 ruler 节点。
- Mimir MultitenantAlermanager 节点挂掉,该实例上不同租户的 alertmanager 实例会被迁移到其它节点,和该租户的其它 alertmanager 实例组成新的集群,默认租户的 alertmanager 复制因子为 3,表示同时有 3 个 alertmanager 实例参与 alert 管理。
实战练习
添加 ruler 和 alertmanager 配置
这里我们还是使用单实例部署方式,ruler 和 alertmanager 相关配置如下:
target: all,alertmanager
ruler:
rule_path: /data/ruler
alertmanager_url: http://127.0.0.1:8080/alertmanager
ring:
# Quickly detect unhealthy rulers to speed up the tutorial.
heartbeat_period: 2s
heartbeat_timeout: 10s
alertmanager:
data_dir: /data/alertmanager
fallback_config_file: /etc/alertmanager-fallback-config.yaml
配置说明:
- target 模式添加 alertmanager,因为该组件是可选项模块, all 模式中并没默认包含。
- ruler 配置中的 alertmanager_url 为 Mimir 的 MultitenantAlermanager 接收地址。
使用 mimir-tool 实现 rules 管理
添加 demo 租户的 rules 配置:
mimir-tool rules load config/rules.yaml --address=http://localhost:9090 --id=demo
config/rules.yaml 配置文件一共包含 16 个 record、1 个 alert 分组。
当 rules 添加完成,我们可以使用 mimir-tool 查看该租户下的所有 rules 信息:
mimir-tool rules list config/rules.yaml --address=http://localhost:9090 --id=demo
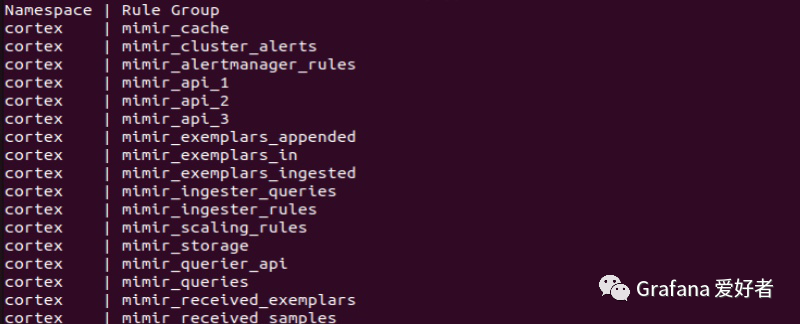
此时我们查看任意一个 mimir 实例的 /data/ruler/demo/mimir 文件将看到只同步了该租户的部分规则分组:

使用 mimir-tool 实现 alertmanager 配置管理
添加 demo 租户的 alertmanager 配置:
cd config/alertmanager && mimir-tool alertmanager load alertmanager.yaml default_templates --address=http://localhost:9090 --id=demo
同样我们也可以使用 mimir-tool 查看租户已经添加的配置:
mimir-tool alertmanager get --address=http://localhost:9090 --id=demo
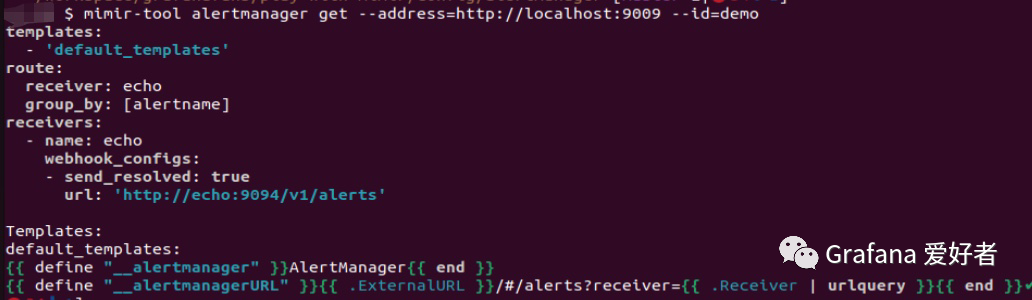
为了测试,这里我们使用 echo webhook receiver 进行告警发送,在实际生产环境中,可以替换为 Email/短信或其它 Receiver。
告警通知测试
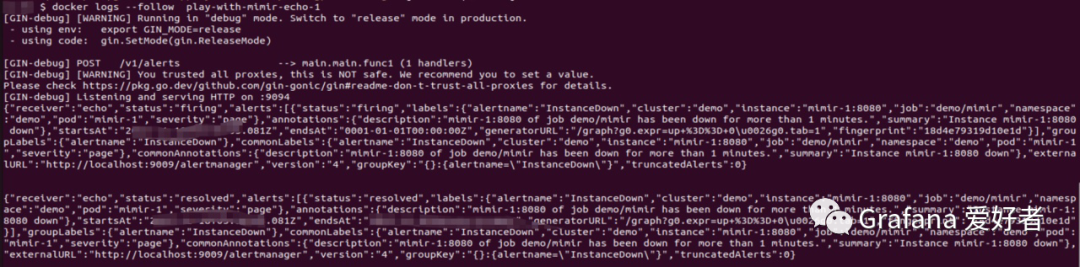
我们在 rules 中配置了一个 instanceDown 的 alert 规则,此时如果我们停掉 mimir-1 实例,等上3分钟,将在 echo 的 log 收到一条 firing 的告警通知,当我们恢复 mimir-1 的时候,将收到 resolved 的通知。
Bonus – Grafana 集成,实现规则和告警可视化管理
Grafana 打通了 Mimir 的规则和告警管理,所以我们可以直接在 Grafana 界面配置 rule 以及 alertmanager,具体流程如下。
配置 alertmanager 数据源
新增 alertmanager 类型数据源,信息如下:
- name: Mimir Alertmanager
uid: alertmanager
type: alertmanager
access: proxy
orgId: 1
url: http://load-balancer:9009/
version: 1
editable: true
jsonData:
httpHeaderName1: 'X-Scope-OrgID'
implementation: 'cortex'
secureJsonData:
httpHeaderValue1: 'demo'
rules 管理和 alertmanager 配置
添加数据源后,我们访问 http://localhost:3000/alerting/list 可以看到刚用 mimir-tool 添加 rules
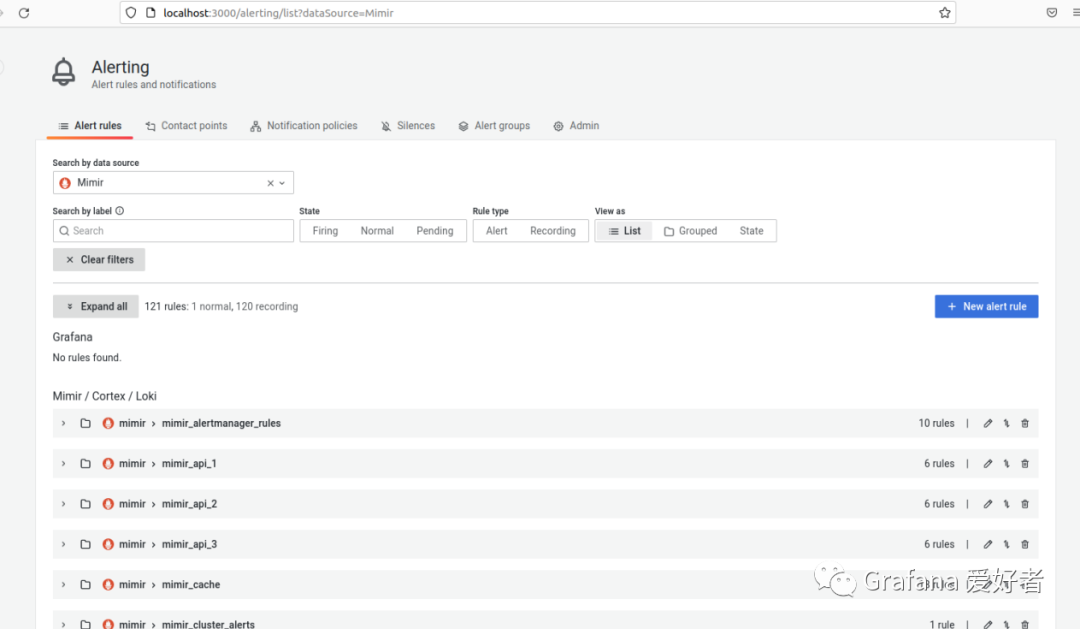
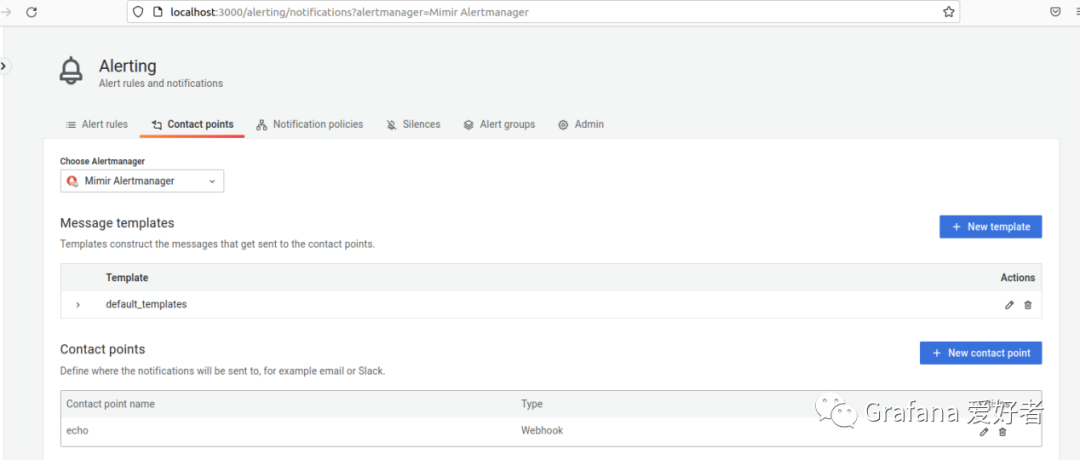
访问 http://localhost:3000/alerting/notifications 可以看到我们刚配置的 alertmanager 相关 receiver 信息:
总结
通过 Mimir 我们非常方便实现 Prometheus 规则评估和告警管理的高可用,它不仅提供了开箱即用的 mimir-tool 实现日常运维管理,还打通了 Grafana 看板,方便租户通过 Grafana 看板进行自定义配置,这样一来 Grafana 看板完全成为一个无状态服务,其规则和告警管理配置数据持续化和一致性由 Mimir 来保障。
相关测试工程已经提交到 https://github.com/grafanafans/play-with-mimir,欢迎大家体验。