本篇是 Prometheus TSDB 系列文章翻译的第一篇,主要介绍头块的工作原理,包括内存活跃 chunk,写到磁盘的内存映射 chunk,以及头块填充满或达到 chunkRange *3/2 时进行截断,压实而创建的持久块等内容。
原文 https://ganeshvernekar.com/blog/prometheus-tsdb-the-head-block
简介
尽管 Prometheus 2.0 大约在3年前就发布了,但除了Fabian的博客 那篇非常高质量的文章之外,再也找不到什么资源可以帮助我们用于了解它的 TSDB,而且关于格式的文档更像是给开发人员用作参考的。
Prometheus 的 TSDB 最近吸引了许多新的代码贡献者,但由于资料的缺乏,了解它已成为一个比较痛苦的事。因此,我计划在一系列文章中详细讨论 TSDB 的工作原理,并介绍一些对贡献者有用的参考代码。
在这篇博客中,我主要讨论 TSDB 的内存部分(头块),当然在后面的文章中我还会更深入地介绍其它组件,例如 WAL 和它的检查点,chunk 的内存映射设计哲学,压实,持久块和它的索引,以及即将推出的 chunk 快照。
前言
Fabian的文章非常适合阅读,能够帮助我们了解 TSDB 的数据模型,核心概念以及顶层设计。他还在2017 年 PromCon 大会上发表了有关演讲。我建议您先阅读那篇文章或看这个演讲,从而打下一个良好的基础,然后再来深入阅读这篇文章。
这篇文章中我提到的一个样本在头块中的所有生命周期相关内容,在我的KubeCon演讲中同样有讲解,如果你愿意的话也可以观看这个演讲。
TSDB 概述
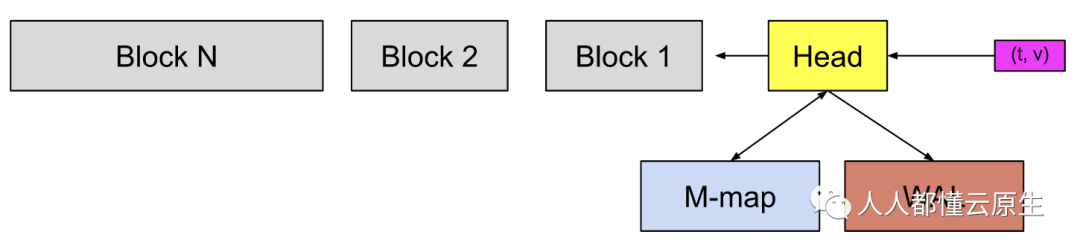
在上图中,头块是数据库的内存部分,灰色块是存在磁盘上的不可更改的持久块。我们有一个预写日志(WAL)用于持久写入。传入的样本(粉红色方框)首先进入头块并在内存中停留一会儿,然后刷新到磁盘并映射到内存(蓝色的方框)。当这些内存映射 chunks 或内存中的 chunks 变旧到一定程度时,它们将作为持久块刷新到磁盘。随着它们变旧,将合并更多的块,并在超过保留期限后被删除。
样本在头块中的寿命
这里的所有讨论都是针对单个时间序列,当然同样适用于其他所有序列。
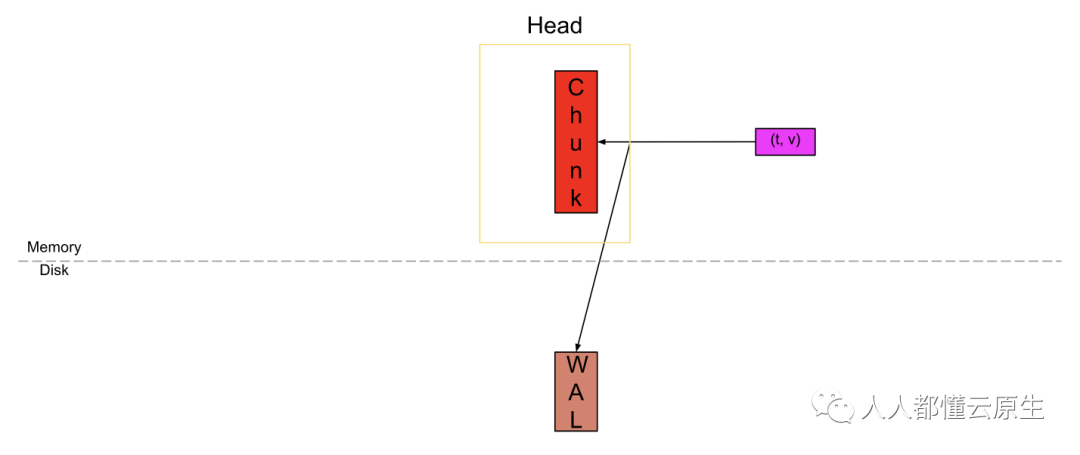
样本存储在称为“Chunk”的压缩单元中。当一个新的样本到来,它将被提取到“活跃 chunk”(红色块)中。它是我们可以主动写入数据的唯一单元。
当新样本提交到这个块(活跃 chunk)的时候,为了确保持久性(意味着即使机器突然崩溃,也可以恢复内存中的数据),我们还将其记录在磁盘(棕色块)的 Write-Ahead-Log(WAL)中。我将另外撰写文章来讲解 Prometheus 是如何处理 WAL 的。
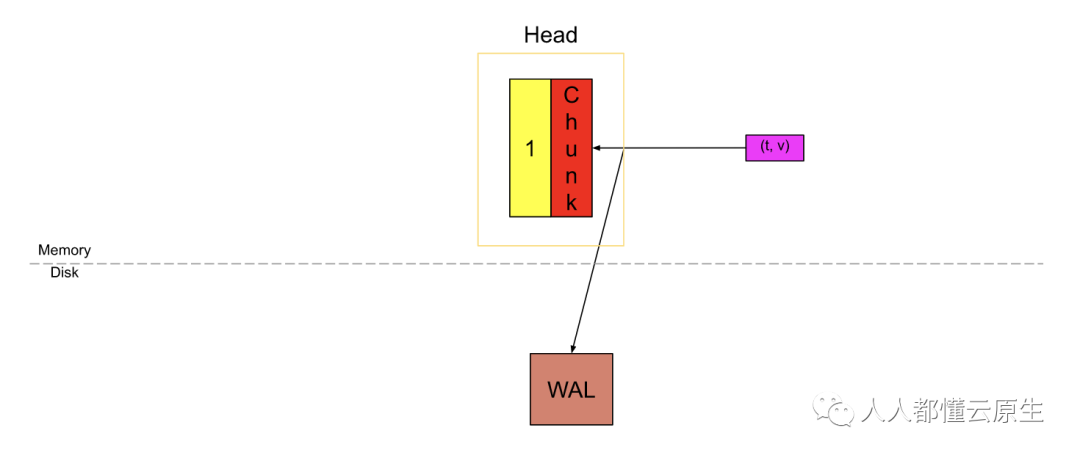
一旦一个 chunk 填满 120 个样本或横跨了 chunk/block 的时间范围(我们把它叫做 chunkRange),默认情况为 2h,此时会剪切出一个新的 chunk,老的 chunk 视为 ”已填满“。例如这篇博文,我们假如拉取的间隔为 15 秒, 那么 120 个样本(一个填满的 chunk)将横跨 30m。
黄色数字为1的块是已填充的完整 chunk,红色块是创建的新 chunk。
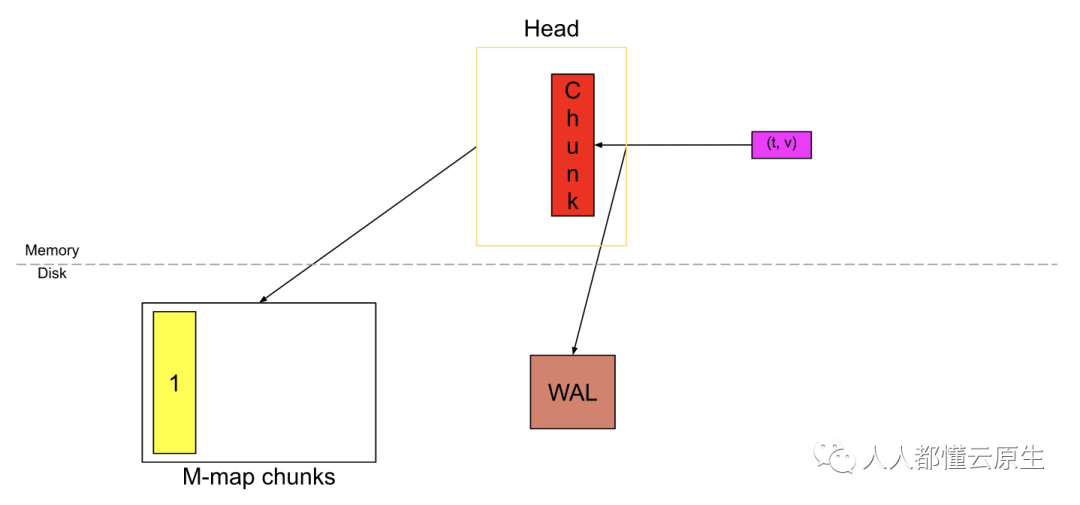
从 Prometheus v2.19.0 开始,我们并不会将所有的 chunk 都存储在内存中。当剪切下新 chunk 后, 已填充的 chunk 将刷新到磁盘并通过磁盘内存映射映射到内存中,内存存储的只是引用而已。使用内存映射,我们可以在需要的时候使用该引用将 chunk 动态加载到内存;这是操作系统提供的功能。
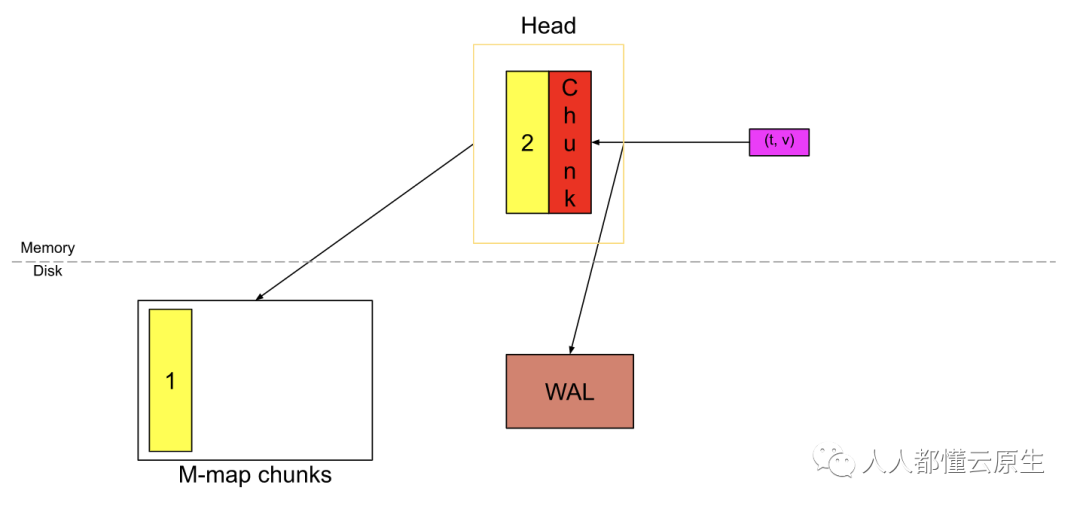
同理,新的样本持续进来,新的 chunk 被剪切。
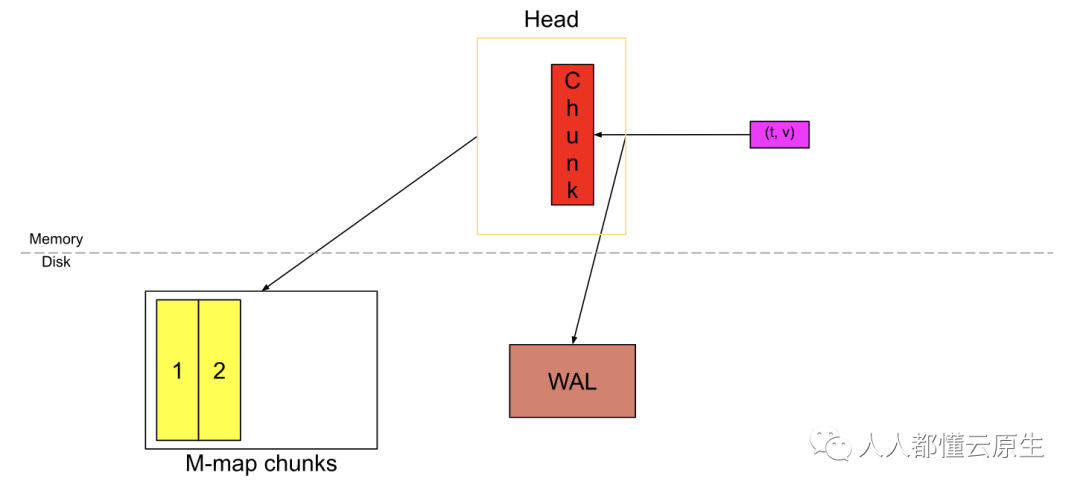
与此同时,这些新的 chunk 被刷新到磁盘并做好内存映射。
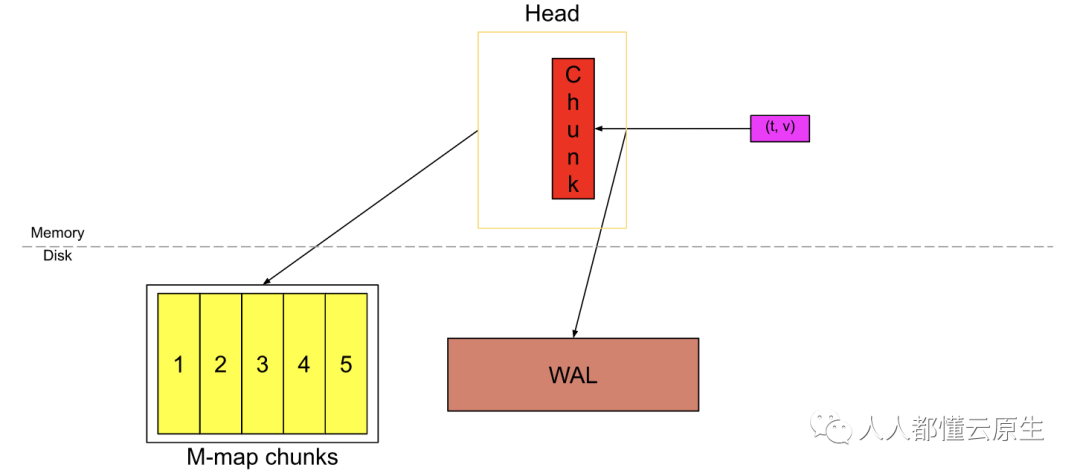
过一段时间后,头块将看起来像上面这样。如果我们认为红色 chunk 也几乎填满,那么头块中有将近 3h 的数据(6个 chunk,每个横跨 30m)。相当于 chunkRange * 3/2。
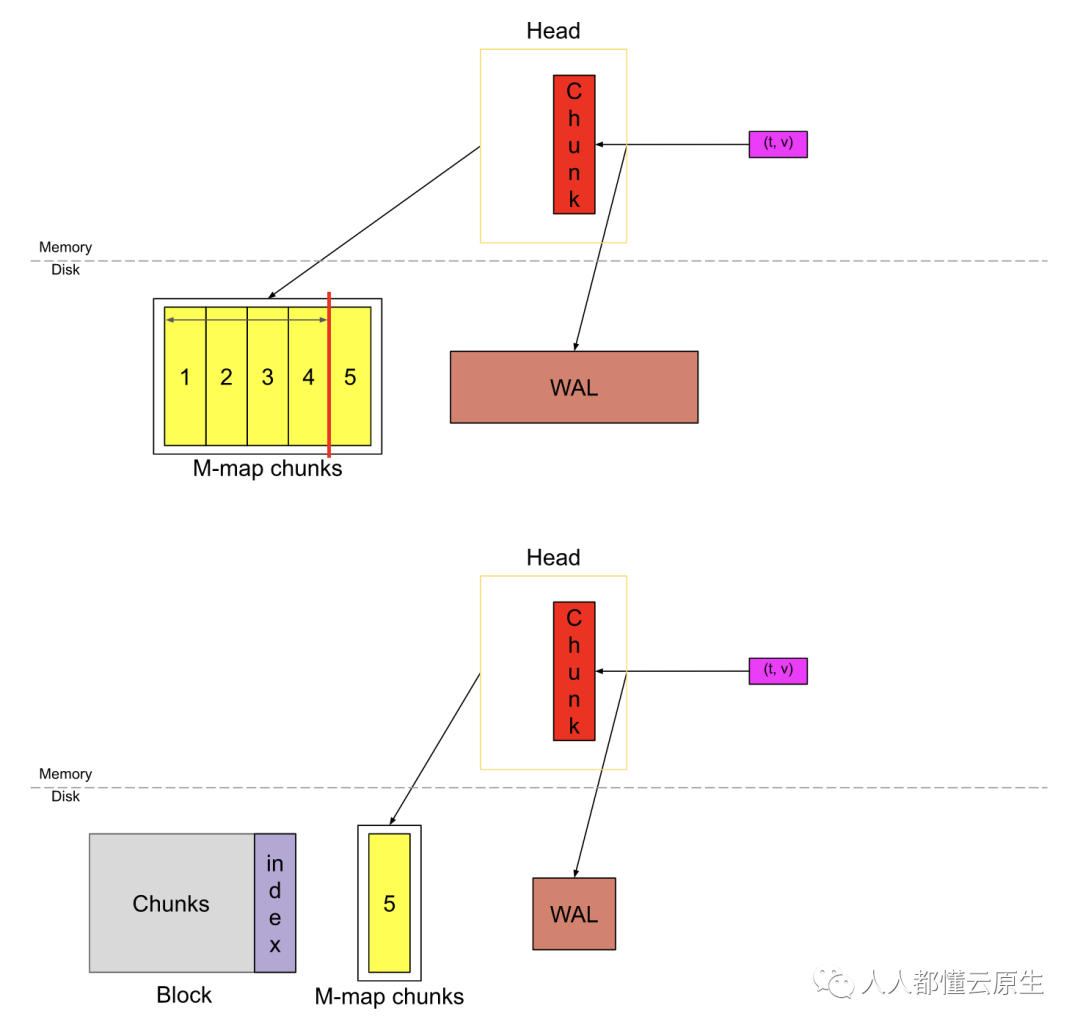
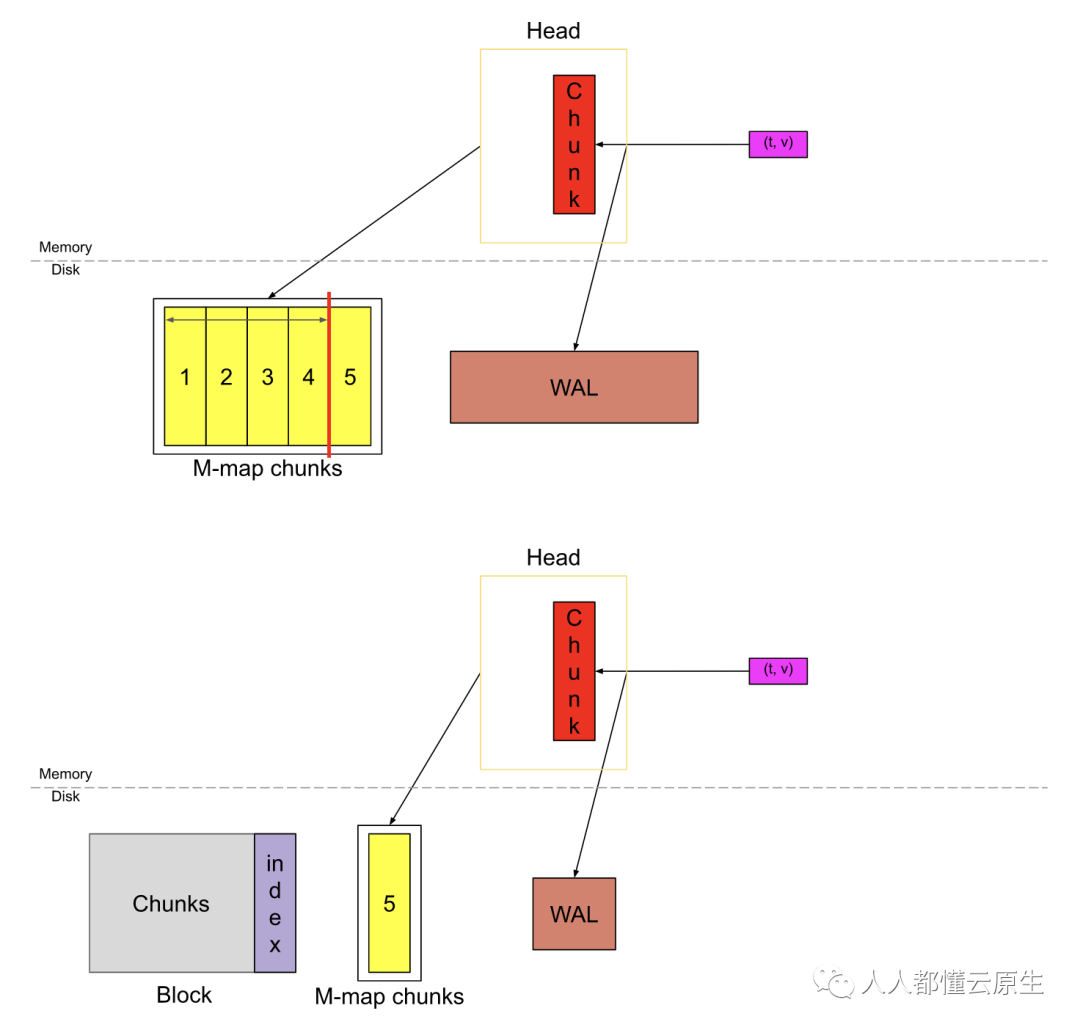
当头块中的数据横跨 chunkRange * 3/2 时,第一个 chunkRange(此处为2h)的数据被压实为一个持久块。如果您注意到上面,WAL 此时将被截断并创建一个“检查点”(图中未显示)。我将在以后的文章中详细介绍这个检查点,WAL截断,压实,持久块以及索引。
不断循环进行样本的采集,内存映射,压实成持久块。这就是头块模型的基本功能。
需要注意/了解的其他事
索引在哪里?
索引以倒排索引的方式存储在内存中。有关索引整体概念的更多内容可以参考 Fabian 的博文。当头块压实并产生持久块时,头块被截断以此删掉老的 chunk,并且对该索引进行垃圾回收,以删除头块中不再存在的所有时序条目。
处理重启
如果 TSDB 必须重新启动(优雅或异常),它将使用磁盘上内存映射的 chunk 以及 WAL 的重放数据和事件,从而重新构建内存中的索引和 chunk。
代码参考
tsdb/db.go 关于 TSDB 的整体功能。
本文相关部分,内存 chunks 提取的核心逻辑全部在 tsdb/head.go 中,它使用 WAL 和内存映射作为黑盒。
关于 TSDB 预期将来会有更多的文章
- WAL 和它的检查点。 Prometheus TSDB (Part 2): WAL 和它的检查点
- 从磁盘映射到内存 chunk 的内存映射。Prometheus TSDB (Part 3): 从磁盘映射到内存 chunk 的内存映射
- 持久块及其索引。Prometheus TSDB (Part 4): 持久块及其索引
- TSDB 的查询。
- 压实。
- 对内存中的 chunk 进行快照,以便在插入时更快地重启。