在 Mimir/Cortex 中,默认一份数据从 distributor 会写3份到不同 ingester 节点,这样做的目的是想通过多副本复制的方式实现数据存储的高可靠。在 Prometheus 生态中,不仅要实现数据存储的高可靠,还要实现数据抓取(Agent/Collector)的高可靠,通常大家也是采用相似的策略,即针对相同配置起多个 Prometheus 实例,然后再将每个实例抓取的结果通过 remote write 推送到同一存储后端。
这样做虽然带来了抓取的高可靠,但如果数据不去重(在一个抓取周期内,distributor 只需转发一个 Prometheus 抓取的数据),每个 Prometheus 示例抓取的指标最终都要转发给 ingester,这会导致 ingester 数据写入量和 compactor block 压缩量翻倍,这将带来资源的浪费。
那该如何去重呢?在 Mimir/Cortex 中主要使用到 distributor 的 HATracker 功能。
HATracker 基本原理
我们先通过二张图了解 HATracker 的基本逻辑。
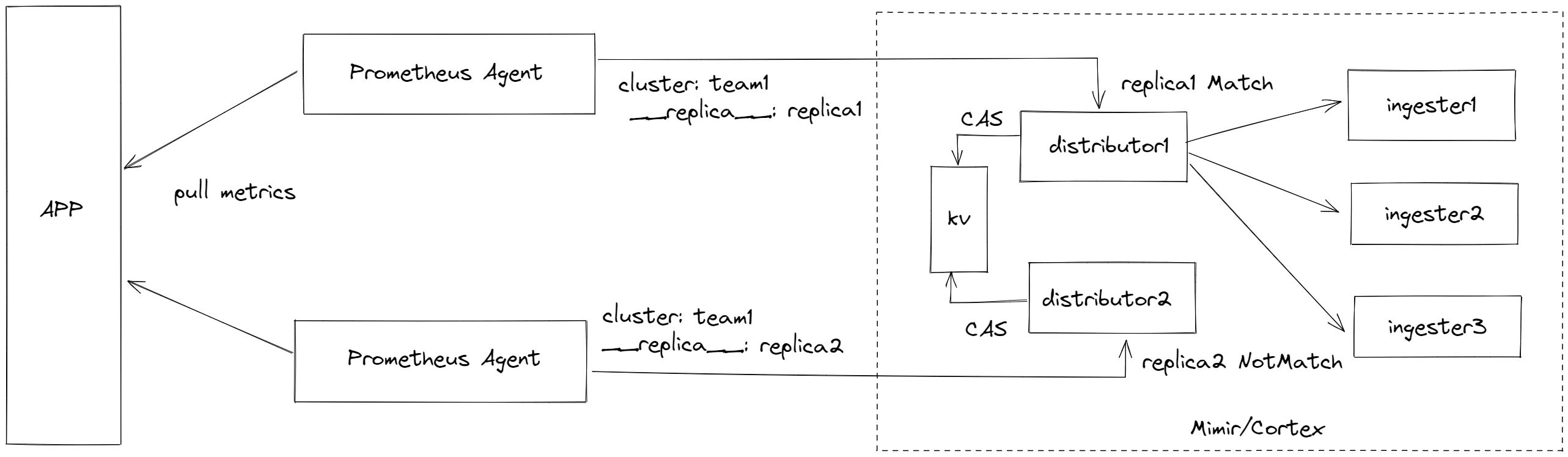
大致流程如下:
- 启动两个 Prometheus Agent 针对同一APP 进行指标抓取。
- 两个 Prometheus Agent 通过 global external_labels 注入 {cluster: team1, replica: replica1/replica2} 的复制组标示,所有的指标都会带上该信息。
- Mimir 开启 HATracker 功能后,distributor 会根据指标的 cluster,replica 分组情况进行 Prometheus Agent 选主,假如这里选择了 replica1 ,并将结果写到 KV (目前只支持 consul 和 etcd)中。
- 以后 distributor 所有节点接收到 Agent 转发的数据,会判断是否来自 replica1, 如果是进行转发(转发数据会删除 replica 标签),如果不是则丢弃。
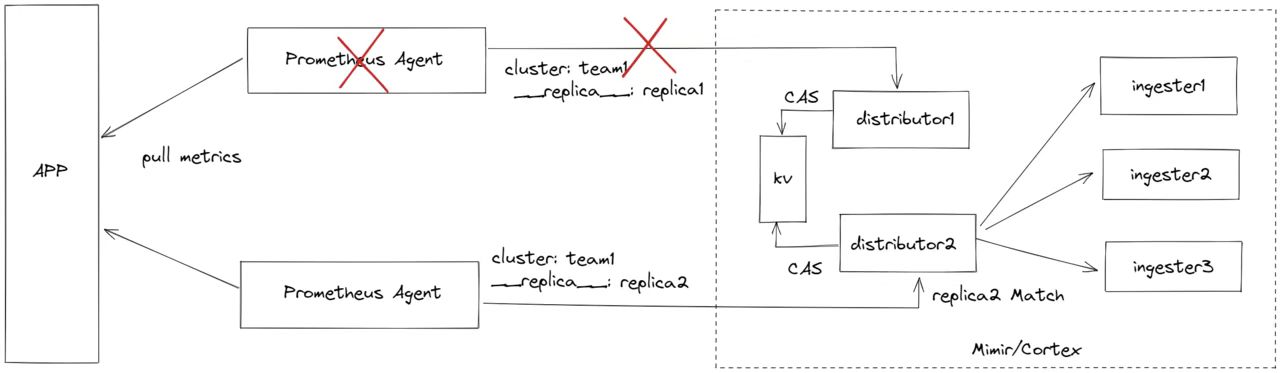
当 replica1 agent 故障后,超过 HATracker 配置的 ha_tracker_failover_timeout 时间,将触发 agent 重新选主,即变为 replica2,并存储到 KV中,以后所有 replica2 agent 的数据会被转发,而待 replica1 恢复后,它上报的数据也只会被丢弃。
可以看到,有了 HATracker ,同一 cluster 的数据,在 distributor 实现了去重,从而只有一个 agent 的数据写到了 ingester。
如何配置
修改 prometheus.yaml,添加 external_labels,内容如下:
global:
external_labels:
cluster: team1
__replica__: replica1
和
global:
external_labels:
cluster: team1
__replica__: replica2
注: 我们可以只使用 Prometheus Agent 模式启动实例,而且可以通过环境变量方式注入 replica 信息。
修改 mimir/cortex distributor 配置,开启 ha_tracker,并配置对应 kvstore。
limits:
accept_ha_samples: true
distributor:
ha_tracker:
enable_ha_tracker: true
kvstore:
store: consul
consul:
host: consul:8500
总结
在实现 Prometheus 高可用方案的时候,不仅要考虑数据存储的可靠性,也要考虑数据抓取的高可靠,Mimir/Cortex 的 HATracker 功能,可以实现多副本 Agent 抓取数据的去重,避免数据写入与数据压缩的翻倍,大大节省了资源。