1. 背景
熟悉 Prometheus 的 TSDB 头块的同学应该都比较清楚,一个时序的写入 chunk 落盘,一般有两种情况:
- chunk 写满120 个采样点,这个 chunk 在写满之前,会一直在内存中,直到写满 120 个样本后,才开始进行 mmap 映射和写磁盘。
- 由于同一个 chunk 不会跨多个 block, 所以即使 chunk 没有写满 120 个点,在写入数据点跨越 block 时间区间边界的时候(默认 2h 倍数),它也会被强制落盘。
2. 问题产生
10 亿指标的冲击
我们以 20s 为间隔,对每一个 series 进行抓取,这样需要 40 分钟就达到 120 个样本,就会触发 chunk 落盘。当 series 少的时候,没有问题,看不出I/O对系统的冲击;但有大量的 series 的时候,每隔 40 分钟,就会有大批 chunks 同时写满,等待落盘,在 10 亿活跃指标的压力下,每 40min 单个写入节点(ingester) 产生7G的数据需要落盘,I/O 问题显而易见。
下图显示了每隔40min,写入延时P99的数据,从10ms,冲到20s-60s。
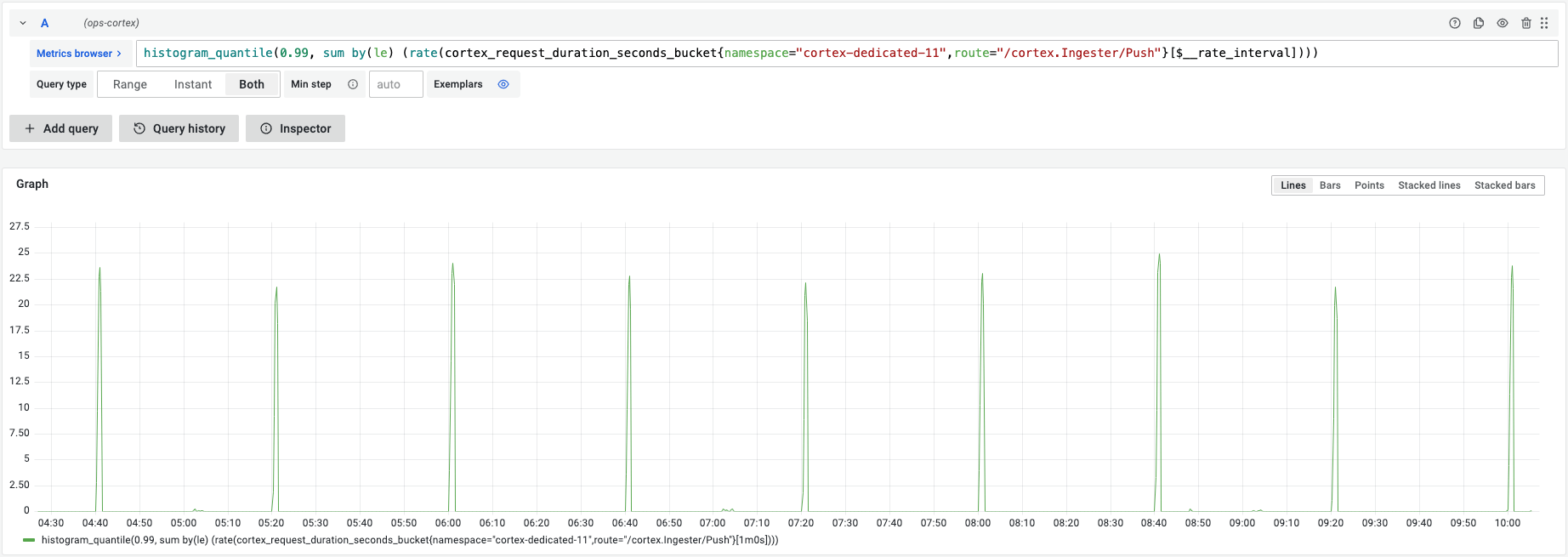
上述I/O 尖刺,是因为在 Prometheus TSDB 中,chunk 的落盘是同步的,这样会导致数据提交处于阻塞,直到所有 chunks 都完成落盘。
具体代码如下: prometheus\tsdb\chunks\head_chunks.go#L421
func (cdm *ChunkDiskMapper) writeChunk(seriesRef HeadSeriesRef, mint, maxt int64, chk chunkenc.Chunk, ref ChunkDiskMapperRef, cutFile bool) (err error) {
...
// if len(chk.Bytes())+MaxHeadChunkMetaSize >= writeBufferSize, it means that chunk >= the buffer size;
// so no need to flush here, as we have to flush at the end (to not keep partial chunks in buffer).
if len(chk.Bytes())+MaxHeadChunkMetaSize < cdm.writeBufferSize && cdm.chkWriter.Available() < MaxHeadChunkMetaSize+len(chk.Bytes()) {
if err := cdm.flushBuffer(); err != nil {
return err
}
}
}
通过阅读源码,我们可以更深刻的理解 TSDB 的 chunk 落盘机制,当大量写满的 series 涌入后,快速的占用公用的 8M 写入缓存(cdm.writeBufferSize),最后再调用 cdm.flushBuffer() 刷新到磁盘,这个过程不断重复导致源源不断的落盘指令被执行着,耗费磁盘I/O。
如果是你,怎么解决
针对上面的问题,我们一般会想到如下解决办法:
1、既然大量指标 40min 同时写满,那么把这个时间进行离散,是不是就能缓解瞬间压力?
时间离散应该能部分缓解写入压力,但只是减少了chunk 同一时间落盘这个概率,如果必须有同一时间落盘的事件触发(样本跨越 block 边界),I/O 尖刺会再次发生。
2、既然公用 8M 的 写入buffer 不够用,是不是提高 buffer 就能缓解呢?
提高 buffer 应该也能缓解压力,但是没有改变阻塞的本质。当 buffer 足够大,内存资源足够充分,应该也能缓解磁盘 I/O 尖刺的问题。
3、既然同步写入阻塞,是不是改成异步会更合适呢?
改成异步,听起来更合适。我们首先要明确一点,chunk 落盘的数据,已经是历史数据,这 120个样本数据何时写到磁盘,只要不影响内存中的最新数据接收,就可以。但是需要解决资源同步的问题,比如当前待落盘的 chunk,需要及时返回当前 chunk 的 mmappedChunks 信息,给其他接口使用。
3. 解决方案
下面我们来看看 Mimir 针对这个问题的解决办法。
3.1 引入jitter
Mimir 做的第一个尝试,是把 120 个样本的硬编码配置,改成可以动态改变的配置 jitter,即每个 sereis 的chunk,判断是否写满,不再严格按照 120 执行,加上一个动态变化的数字,您可以认为,它把海量的 series 的 chunk 落盘做到了时间离散化。
具体代码参考 prometheus\tsdb\head_append.go 的 addJitterToChunkEndTime 函数:
func (s *memSeries) append(t int64, v float64, appendID uint64, chunkDiskMapper chunkDiskMapper) (delta int64, sampleInOrder, chunkCreated bool) {
...
if numSamples == samplesPerChunk/4 {
maxNextAt := s.nextAt
s.nextAt = computeChunkEndTime(c.minTime, c.maxTime, maxNextAt)
s.nextAt = addJitterToChunkEndTime(s.hash, c.minTime, s.nextAt, maxNextAt, s.chunkEndTimeVariance)
}
...
}
提交记录在这里,grafana/mimir#495 中引入 jitter 的方法,在当前版本还在使用,它可以部分缓解磁盘 I/O 高的问题。
下图显示了引入jitter后,磁盘I/O的尖刺数从 3 次变成 1 次。
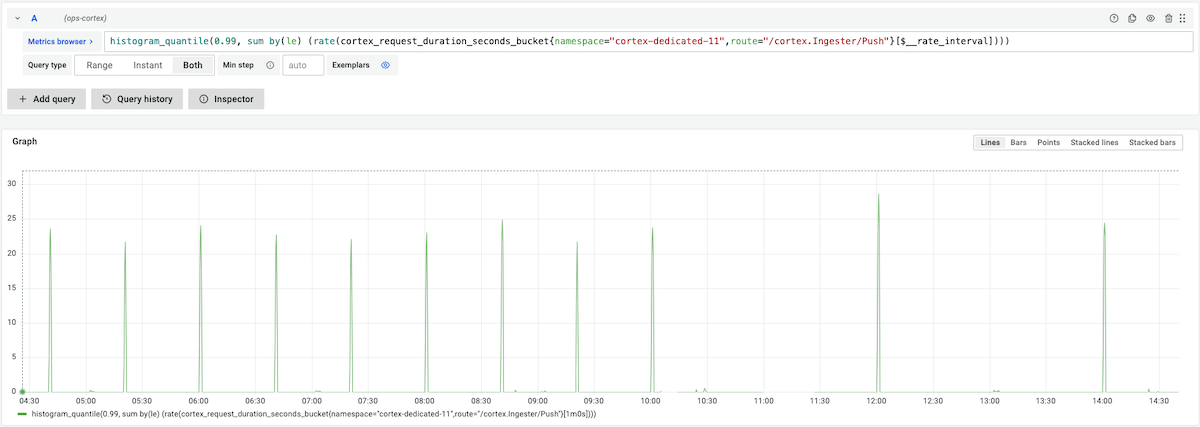
可以看到,从8点到10点,不包含8点,有3个尖刺。10点半以后,引入新版本,看到从12点到14点,只有14点1个尖刺。其中12点和14点的尖刺,是到达2h整点,还未写满120个sample的chunk落盘导致的。
之所以说,部分缓解磁盘 I/O 高的问题,因为chunk 不能跨越block 边界,导致时间窗口(默认2h)到达边界后,所有 chunk 必须被截断。所以当append 数据的时候,就需要根据这个集合, [2h整点,s写满120个samples的预期时间] 进行取小操作,限制chunk必须2h对齐的代码如下:
mimir\vendor\github.com\prometheus\prometheus\tsdb\head_append.go
func (s *memSeries) append(t int64, v float64, appendID uint64, chunkDiskMapper chunkDiskMapper) (delta int64, sampleInOrder, chunkCreated bool) {
...
numSamples := c.chunk.NumSamples()
if numSamples == 0 {
// It could be the new chunk created after reading the chunk snapshot,
// hence we fix the minTime of the chunk here.
c.minTime = t
s.nextAt = rangeForTimestamp(c.minTime, s.chunkRange)
}
...
if t >= s.nextAt || numSamples >= samplesPerChunk*2 {
c = s.cutNewHeadChunk(t, chunkDiskMapper)
chunkCreated = true
}
3.2 chunk异步落盘
为了更好的解决磁盘I/O的问题,Mimir 修改了 TSDB的落盘逻辑-把 chunk 落盘放在一个队列里完成,即实现了异步落盘,同时,查询不受影响。
异步落盘代码如下:
mimir\vendor\github.com\prometheus\prometheus\tsdb\chunks\head_chunks.go
// WriteChunk writes the chunk to the disk.
// The returned chunk ref is the reference from where the chunk encoding starts for the chunk.
func (cdm *ChunkDiskMapper) WriteChunk(seriesRef HeadSeriesRef, mint, maxt int64, chk chunkenc.Chunk, callback func(err error)) (chkRef ChunkDiskMapperRef) {
...
if cdm.writeQueue != nil {
return cdm.writeChunkViaQueue(ref, cutFile, seriesRef, mint, maxt, chk, callback)
}
...
针对这部分代码,Mimir 已向 Prometheus 提了 PR,并合并了,具体参考 Prometheus代码。但这个功能默认关闭,如果你恰好有这个问题,不妨尝试修改配置,试用一下,对应修改配置如下:
// DefaultWriteQueueSize is the default size of the in-memory queue used before flushing chunks to the disk.
// A value of 0 completely disables this feature.
DefaultWriteQueueSize = 0
(请注意,上面的jitter方案,当前还没有提交给 Prometheus 提交)。
为了验证 TSDB 的 chunks 落盘时延,我们对比的部署了两种场景:在 A 区的抓取模块开启异步落盘,在 B 和 C 区使用同步落盘代码(jitter机制仍然存在)。下图显示了异步落盘队列,将 P99 的延时从 45s 降低到 3s。
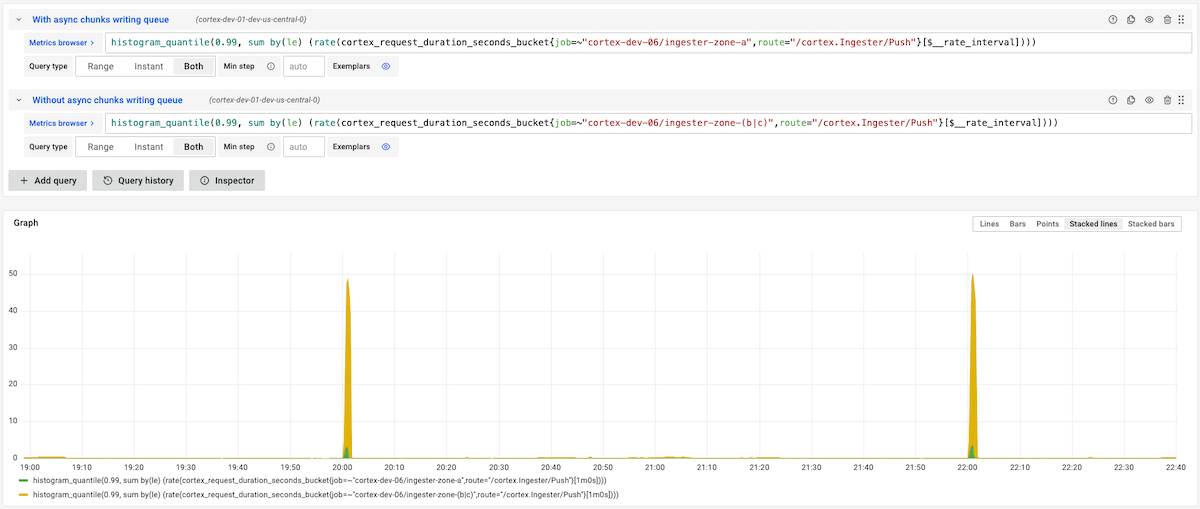
【从20点到22点,绿色图线代表异步落盘机制引入后的尖刺情况,黄色图线代表只有 jitter 机制下的尖刺情况。】
4.总结
通过看 Mimir 对磁盘 I/O 的尖刺问题处理,我们可以有几点启发:
- 分布式系统,处理批量事件的时候,离散化处理,是一个简单有效的思路
- 磁盘并发写高的时候,如何进行异步化改造,是一个永恒的话题。
现在打开你的 Grafana 监控面板,查看 Prometheus 的磁盘 I/O 情况,如果也出现尖刺,可以考虑使用上面的方案,进行解决。