Mimir compactor组件负责将抓取模块ingester上传的多个TSDB blocks,合并成大的block,即从level1-levelN的压缩过程。当处理亿级活跃指标压缩数据时,会出现一系列挑战性的问题。
问题场景
首先,原有的compactor不能均衡的处理压缩任务。起初,Mimir 团队使用企业版的compactor,它可以很好地将跨时间段(默认2h)的数据进行压缩,但是当压缩2h内level1的原始数据的blocks时,却花费了很长时间,因为10亿活跃指标,2h内产生的block是非常多的。这样带来的一个后果就是,由于2h内的数据没有压缩、去重,查询性能也比较差。
然后,即使compactor能够完成压缩,最后结果也是异常。因为当前TSDB格式中,有内容大小的限制。比如index最大可以写64G,index内部的功能分区section的大小限制为4BYTE=2^32,最大占用4G。关于index详细格式,参考链接。 作者在生产环境中也遇到symbol label限制的问题,由于当时section报错没有打印,所以提交PR增加了这个错误。但是index的限制问题,prometheus社区还在讨论中,因为涉及TSDB数据落盘和历史数据兼容的问题。
split-and-merge 压缩
为了克服上述的问题和限制,Mimir提出一种新的压缩算法,叫做split-and-merge压缩。这种方法支持水平和垂直扩展,尤其是在同一时间段内的数据压缩有明显效果。总体来说,包含三个步骤:group(分组)-split(拆分)-merge(压缩)
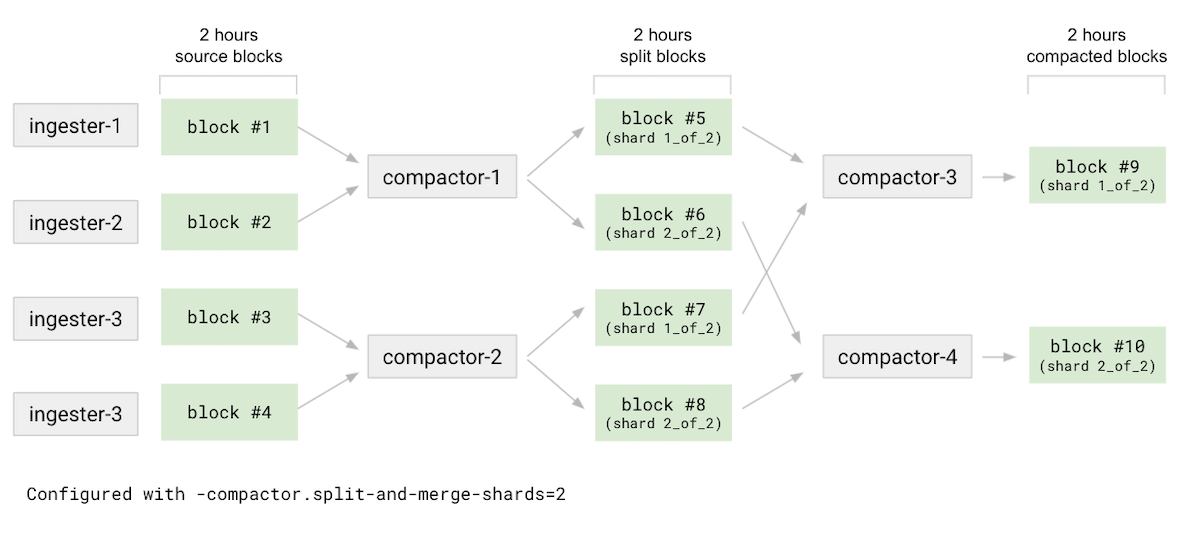
group
首先将源blocks进行分组(需要注意group前的blocks是所有Ingester模块上传到对象存储的2h原始数据块),然后每个compactor分配一些“预压缩”任务,比如compator-1负责压缩block#1和block#2 ,compator-2负责压缩block#3和block#4 ,这样compator-1和compator-2可以并行工作。
对于原始未压缩的2h数据,打上stageSplit状态
/home/opensource/mimir/pkg/compactor/split_merge_grouper.go
//blockrange configuration:
cfg.BlockRanges = mimir_tsdb.DurationList{2 * time.Hour, 12 * time.Hour, 24 * time.Hour}
func planCompaction(userID string, blocks []*metadata.Meta, ranges []int64, shardCount, splitGroups uint32) (jobs []*job) {
planCompactionByRange(userID, mainBlocks, tr, tr == ranges[0], shardCount, splitGroups)
...
if splitJobs := planSplitting(userID, group, splitGroups); len(splitJobs) > 0 {
// start to produce groups
splitGroup := mimir_tsdb.HashBlockID(block.ULID) % splitGroups
if jobs[splitGroup] == nil {
jobs[splitGroup] = &job{
userID: userID,
stage: stageSplit, // split stage
shardID: sharding.FormatShardIDLabelValue(uint64(splitGroup), uint64(splitGroups)),
blocksGroup: blocksGroup{
rangeStart: group.rangeStart,
rangeEnd: group.rangeEnd,
},
}
}
请注意,上面的shardID索引是根据splitGroup := mimir_tsdb.HashBlockID(block.ULID) % splitGroups
可能得到如下jobs的shardID信息:
shardID=1_of_2; // group-1
shardID=2_of_2; // group-2
需要设置shardID分配任务,因为任务执行时,需要shardingKey,来保证不同的group被不同的compactor执行。
func (j *job) shardingKey() string {
return fmt.Sprintf("%s-%s-%d-%d-%s", j.userID, j.stage, j.rangeStart, j.rangeEnd, j.shardID)
}
最后生成了本次groups的任务,
//home/opensource/mimir/pkg/compactor/split_merge_grouper.go
func (g *SplitAndMergeGrouper) Groups(blocks map[ulid.ULID]*metadata.Meta) (res []*Job, err error) {
compactionJob := NewJob(
g.userID,
groupKey,
externalLabels,
resolution,
metadata.NoneFunc,
job.stage == stageSplit, // mark this a split job
g.shardCount,
job.shardingKey(),
)
//such jobs are executed by compactors
此任务随后被compactors执行,具体被compators集群中的哪个节点执行该任务,可以跟踪一下func (s *splitAndMergeShardingStrategy) ownJob(job *Job) 函数 。后面我们再单独分享一次,jobs的分解和执行逻辑。
split
对于compator-1,根据分组产生的预压缩任务,下载block#1和block#2到本地后,再按照配置的split-and-merge-shards值(这里配置为2),根据sereis的label进行hash分成2份,产生了block#5(shard 1_of_2)和 block#6(shard 2_of_2)。这里的block#5和block#6随后将被上传到对象存储。
===>split
/home/opensource/mimir/pkg/compactor/bucket_compactor.go
func (c *BucketCompactor) runCompactionJob(ctx context.Context, job *Job) (shouldRerun bool, compIDs []ulid.ULID, rerr error) {
if job.UseSplitting() {
compIDs, err = c.comp.CompactWithSplitting(subDir, blocksToCompactDirs, nil, uint64(job.SplittingShards()))
然后修改了tsdb压缩部分,传进去shardCount参数,这里是为了构造shard数据。
###modify prometheus tsdb compact codes by adding #shardCount :
/home/opensource/mimir/vendor/github.com/prometheus/prometheus/tsdb/compact.go
func (c *LeveledCompactor) compact(dest string, dirs []string, open []*Block, shardCount uint64) (_ []ulid.ULID, err error) {
func (c *LeveledCompactor) write(dest string, outBlocks []shardedBlock, blocks ...BlockReader) (err error) {
func (c *LeveledCompactor) populateBlock(blocks []BlockReader, minT, maxT int64, outBlocks []shardedBlock) (err error) {
if len(outBlocks) > 1 {
obIx = s.Labels().Hash() % uint64(len(outBlocks)) // obIx = shard index,outBlocks=shard counts
}
####return from prometheus tsdb compact
最主要的是上面的obIx部分,这个数据就是某个series被分配到哪个shard的唯一根据。outBlocks的个数,就是shardcounts的配置值。
obIx = s.Labels().Hash() % uint64(len(outBlocks)) // obIx = shard index,outBlocks=shard counts
最后将每个split完的block,加上”compactor_shard_id“标签,然后被推送到持久化存储。
//CompactorShardIDExternalLabel = "__compactor_shard_id__"
//block meta info add shard label, like "__compactor_shard_id__": "2_of_2"
if job.UseSplitting() {
newLabels[mimit_tsdb.CompactorShardIDExternalLabel] = sharding.FormatShardIDLabelValue(uint64(blockToUpload.shardIndex), uint64(job.SplittingShards()))
}
//such blocks then will be uploaded to buckets.
merge
上面split完的shard:1_of_2,包含block#5和block#7,然后由compactor-3对这两个block的数据进行压缩,生成1个2h的分片block#9。同理,由compactor-4生成另外1个分片,block#10。
经过上述步骤,tenant中的2h原始数据,被切分成两个level2的block,随后的level3-levelN的压缩,会由compactor-x继续执行merge的动作,同时分别保持1_of_2和2_of_2的label。
merge时仍然需要先创建任务,这时候的stage,就是stageMerge
======> merge
handle "__compactor_shard_id__" labeled blocks
func planCompactionByRange(userID string, blocks []*metadata.Meta, tr int64, isSmallestRange bool, shardCount, splitGroups uint32) (jobs []*job) {
...
func groupBlocksByShardID(blocks []*metadata.Meta) map[string][]*metadata.Meta {
shardID := block.Thanos.Labels[mimir_tsdb.CompactorShardIDExternalLabel]
groups[shardID] = append(groups[shardID], block) // produce merge groups by CompactorShardIDExternalLabel
jobs = append(jobs, &job{
userID: userID,
stage: stageMerge, // merge stage
shardID: shardID,
blocksGroup: blocksGroup{
rangeStart: group.rangeStart,
rangeEnd: group.rangeEnd,
blocks: shardBlocks, // shardBlocks only has one label type like "1_of_2" or "2_of_2"
},
})
//compact merge blocks by shardBlocks belonging same __compactor_shard_id__.
func (c *BucketCompactor) runCompactionJob(ctx context.Context, job *Job) (shouldRerun bool, compIDs []ulid.ULID, rerr error) {
...
// used for splitting
if job.UseSplitting() {
compIDs, err = c.comp.CompactWithSplitting(subDir, blocksToCompactDirs, nil, uint64(job.SplittingShards()))
}
// used for merging
else {
var compID ulid.ULID
compID, err = c.comp.Compact(subDir, blocksToCompactDirs, nil) // execute normal compaction
compIDs = append(compIDs, compID)
}
如何开启分片压缩
关键配置信息
-compactor.split-groups:分组数配置
-compactor.split-and-merge-shards:分组后,每个block进行分片的个数,以及最终merge后产生的分片数。
-compactor.compactor-tenant-shard-size: 多租户场景下,每个租户可以使用的compactor实例个数。默认为0,不限制使用个数。
-compactor.compaction-concurrency: 每个compactor实例可以同时开启的压缩线程数
一个例子
我们前面章节使用 docker-compose 一键部署单体版集群介绍的3节点集群部署的单体模式为基础,修改overrides.xml文件中,demo租户的compator分片配置,
overrides:
demo:
compactor_split_and_merge_shards: 2
compactor_split_groups: 2
重新部署,经过2h后,compactor开始工作,在/data-compactor/compactor-meta-demo/meta-syncer 目录下,可以看到meta.json的信息。压缩后的blocks,已经上传到对象存储,如需查看具体的block可以去minio控制台查看。
01G87DF5RCC2HT585HPR7J7TWN/meta.json: "__compactor_shard_id__": "2_of_2"
01G87DF6CAKB3PKV66R9CDJPXW/meta.json: "__compactor_shard_id__": "2_of_2"
01G87DF6QKSE4Z2MS028J7YCTV/meta.json: "__compactor_shard_id__": "2_of_2"
01G87EST3SF17E8SEEJ76VFTY2/meta.json: "__compactor_shard_id__": "1_of_2"
某个level2的meta.json文件内容如下,可以看到”compactor_shard_id”: “2_of_2”的标签表示本次block包含的是series_hash % shard_count 为2的内容。
"compaction": {
"level": 2,
"sources": [
"01G87M05RRTFTMGFMZD8BENZXH"
],
"parents": [
{
...
}
]
},
"version": 1,
"thanos": {
"labels": {
"__compactor_shard_id__": "2_of_2"
},
"downsample": {
"resolution": 0
},
"source": "compactor",
总结
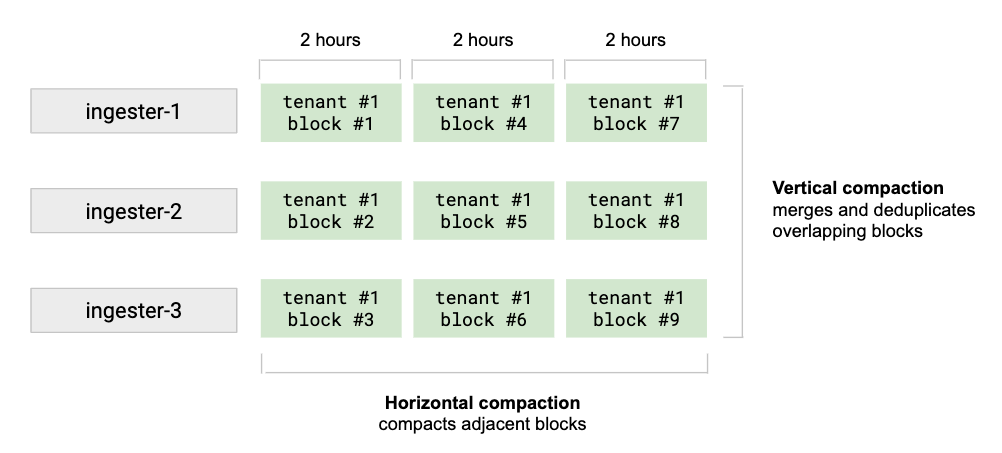
对于split-merge分片压缩,大量任务可以由多台compactor实例提供分布式的方式,并发执行。
即,当某个租户的指标很多时,可以配置较多的groups,split-and-merge-shards参数:
进行2h内的垂直分片合并,在merge生成Level1数据时,是基于每个分片的维度独立进行的。这样可以快速完成多副本数据合并;
进行2h外的水平分片合并,即Level2-LevelN压缩时,也会保持较高的效率和性能。
可以说,水平压缩的高效,得益于垂直压缩的分片。
下图显示了150台compactor实例,压缩单租户10亿指标的数据,
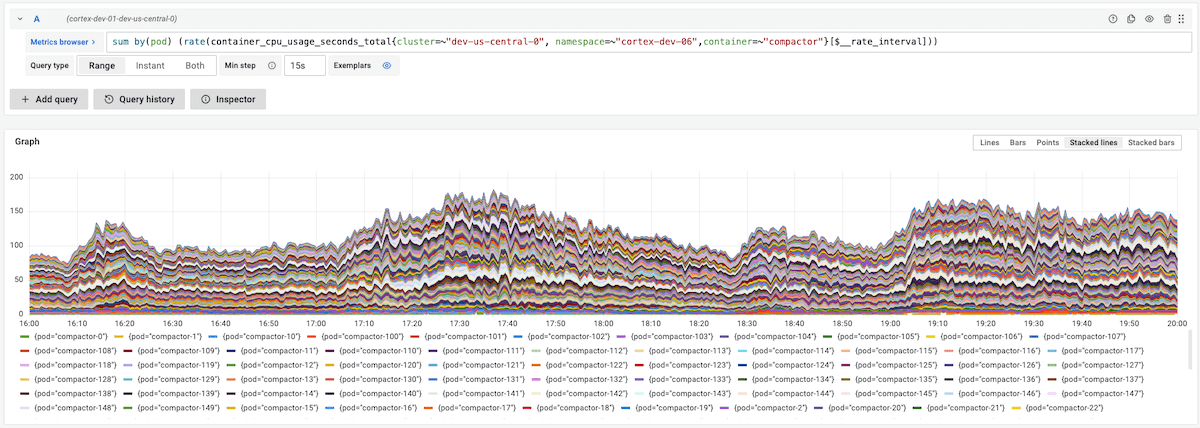
可以看出所有compactor的压力比较均衡。水平和纵向压缩,可以保证查询时,不访问非压缩的block。