根据上一篇内容,Mimir 源码分析 (四):算子下推–高基数分片查询 ,我们先复习一下查询相关的分片配置:
- query-front是否开启分片查询配置:
frontend:
parallelize_shardable_queries:true
- query-front查询分片数配置:
query_sharding_total_shards: 16
query_sharding_max_sharded_queries: 128
- 压缩分片配置:
overrides:
demo:
compactor_split_and_merge_shards: 3
compactor_split_groups: 2
我们看到,查询压缩数据时,有如下6种场景:
- 查询分片未开启,压缩分片未开启
- 查询分片未开启,压缩分片开启
- 查询分片开启,压缩分片未开启
- 查询、压缩分片开启,查询分片=压缩分片数
- 查询、压缩分片开启,查询分片是压缩分片的倍数
- 查询、压缩分片开启,压缩分片是查询分片的倍数
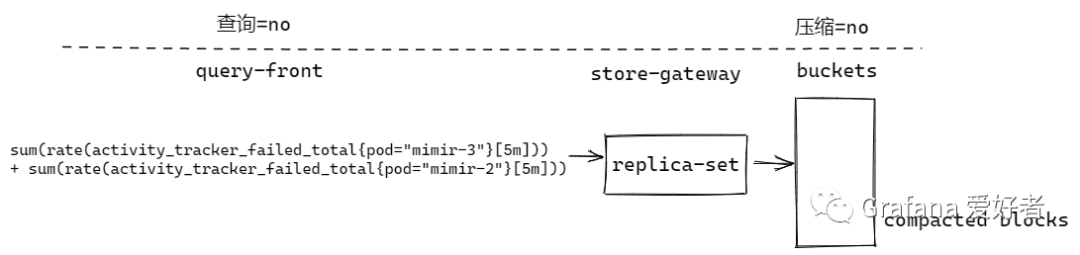
查询分片未开启,压缩分片未开启
query-front 不拆分查询语句,store-gateway 去一块 compacted blocks 读数据。
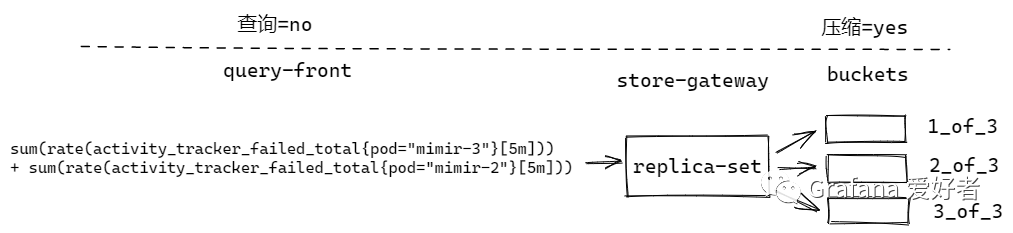
查询分片未开启,压缩分片开启
query-front 不拆分查询语句, store-gateway 根据 replica-set 的个数,轮询到多个 compacted blocks 读数据。
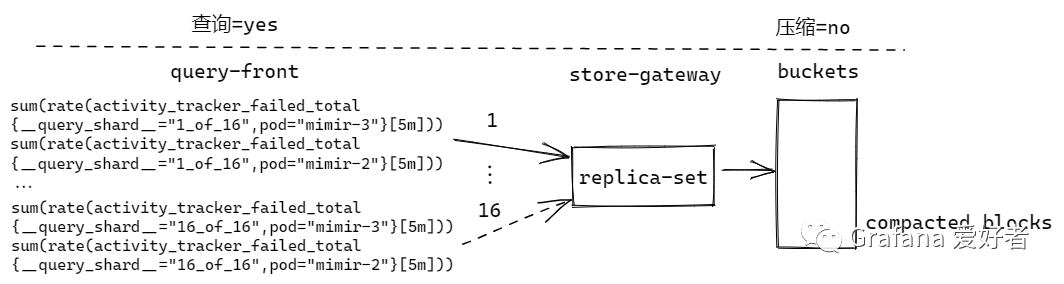
查询分片开启,压缩分片未开启
query-front 按照16拆分查询语句,但是因为压缩分片未开启,最终只有第一组查询语句被 store-gatway 执行去 buckets 获取 compacted blocks。
查询、压缩分片开启,查询分片=压缩分片数
query-front 按照16拆分查询语句,压缩也按照16进行分片。
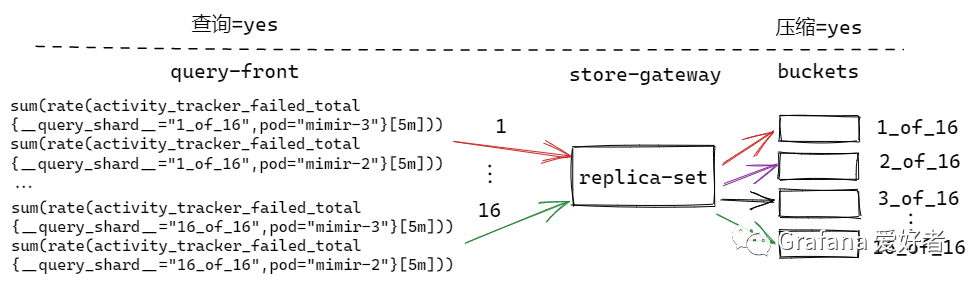
那么最终会生成32个查询任务。即红色的查询有两个任务,因为{query_shard=”1_of_16”,pod=”mimir-3”} 和 {query_shard=”1_of_16”,pod=”mimir-2”} 分别绑定一次 buckets 的 1_of_16分片。每一个 store-gateway 分组节点,默认按照负载均衡的方式,让某一个 store 执行查询任务。同理,绿色的查询也有两个任务。
查询、压缩分片开启,查询分片是压缩分片的倍数
query-front 按照 16 拆分查询语句,压缩按照 4 进行分片。
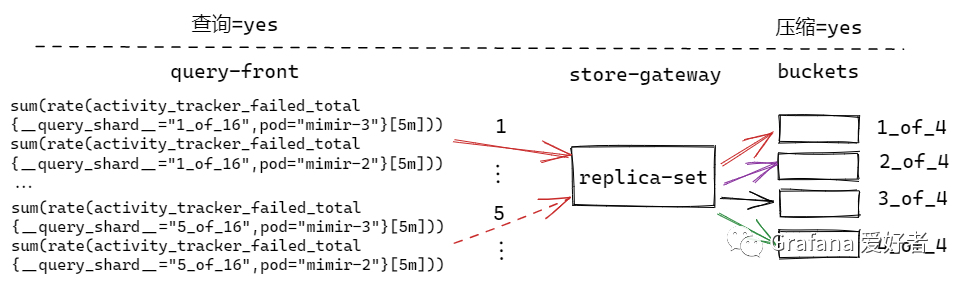
红色的查询有2个任务,和上面一种情况类似, {query_shard=”1_of_16”,pod=”mimir-3”} 和 {query_shard=”1_of_16”,pod=”mimir-2”} ,都需要分别绑定一次 buckets 的 1_of_16 分片。
但是当处理 shard=5 的查询分片时, {query_shard=”5_of_16”,pod=”mimir-3”} 和 {query_shard=”5_of_16”,pod=”mimir-2”} ,因为5%4=1,对于1_of_16来说,已经在分组1中处理过一次,所以不会再分配store任务。
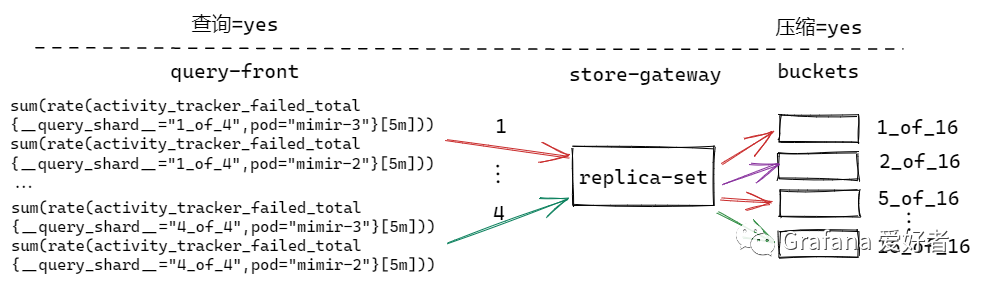
查询、压缩分片开启,压缩分片是查询分片的倍数
query-front 按照 4 拆分查询语句,压缩按照 16 进行分片。
总结
通过上述查询场景我们看出:
- 查询总数,即 store 的查询总次数,是由压缩分片个数决定的。
- 查询分片配置<=压缩分片个数,是有意义的。同时查询配置是租户级别的配置,当查询分片较少时,该租户出现的大量查询任务会排队,当查询分片较多时,因为每一个查询go routine的耗时更小,可以更快的响应其他查询任务。